
layout: post title: ‘Segmenting, localizing and counting object instances in an image’ —
When we visually perceive the world, we may get a large amount of data. If you take a picture with a modern camera it is > 4 Million pixels and several megabytes of data.
But really in a picture or scene there is little interesting data we humans consume. It is task dependent, but for example in a scene we look for other animals and humans, their location, their actions. We may look for faces to gage emotions, or intensity and gravity of actions to understand the situation in the overall scene.
When driving, we look for traversable road, behavior of other vehicles, pedestrians and moving objects, and pay attention to traffic signs, lights and road markings.
In most cases, we look for a handful of objects, their x,y,z position, and reject the vast majority of what we call background. Background is anything our task does not require to attend to. People can be background if we are looking for our keys.
Sometimes we also need to count, and be able to tell how many objects of one kind are present, and where they are.
In most cases we look at a scene and want to get this information:
Ideal segmentation, localization and instance counting in a visual scene. Segmentation gives precise boundaries of object instances, a much more refined approach that bounding boxes.
We may also want to get more tailed information on a second glance, for example facial key-points, position of skeletal key-points in a human figure, and more. An example:
Our facial keypoints detector neural network in action
We will now review how this can be done with neural networks and deep learning algorithms.
We should understand that human vision works on multiple passes on the visual scene. This means we recursively observe the visual scene in waves,first to get the most crude content in the minimum time, for time sensitive tasks. Then we may glance again and again to find more and more details, for precision tasks. For example in a driving situation we want to know if we are on the road and if there are obstacles. We look at rough features for a fast response. We are not interested in the color or make/model of the car we are about to hit. We just need to brake fast. But if we are looking for specific person in a crowd, we will find people first, and then find their face, and then study their face with multiple glances.
Neural network need not follow the rules and ways of the human brain, but generally it is a good idea to do so in the first iteration of algorithms.
Now, if you run a neural network designed to categorize objects in a large image, you will get several maps at the output. These maps contain the probability of the objects presence in multiple location. But because categorization neural network want to reduce a large amount of pixels to a small amount of data (categorize), then they also lose the ability to precisely localize object instances — to some extent. See example below:

Neural network raw output on a large image: probability of person category
Note that the output you get is “for free” meaning we do need to run any other algorithms beside the neural network to find localization probabilities. The resolution of the output map is usually low, and depends on the neural network , its input trained eye size, and the input image size. Usually this is rough, but for many tasks it is enough. What this does not give you is precise instance segmentation of all objects, and precise boundaries.
To get the most precise boundaries, we use segmentation neural networks, such as our LinkNet, here modified to detect many different kinds of image key-points and bounding boxes.:
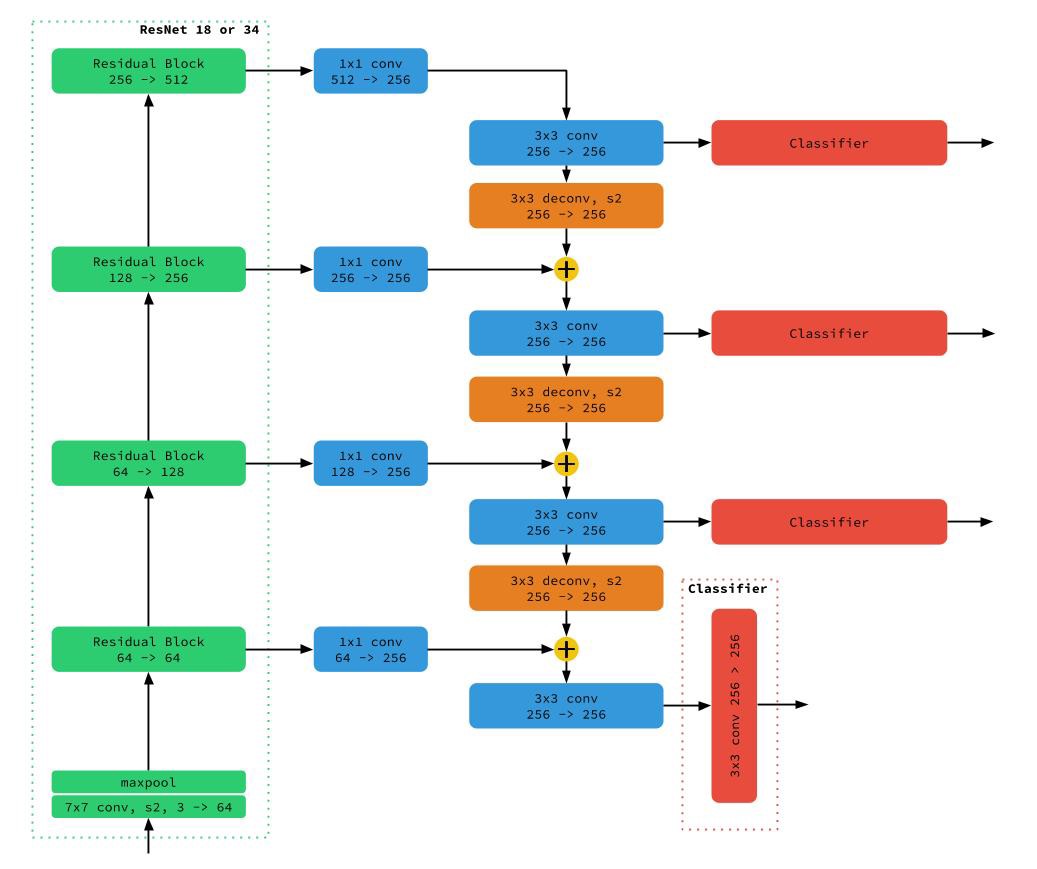
Our Generative Ladder Network used to detect key-points in an image (facial, bounding boxes, body pose, etc…). This uses a special new network architecture designed for maximum efficiency.
These kind of neural networks are Generative Ladder Networks that use an encoder as a categorization network and a decoder to be able to provide precise localization and image segmentation on the input image plane.
This kind of network gives the best performance for simultaneously identifying, categorizing and localizing any kind of objects.
Here are results we can obtain with Generative Ladder Networks:

Typical results obtained with LinkNet and Generative Ladder Networks — see videos here
Generative ladder networks are not very computationally heavy, because the encoder is a standard neural network, and can be designed to be efficient, like eNet or LinkNet. The decoder is an upsampling neural network that can be made asymettrically fast and computationally inexpensive, such as in eNet, or use bypass layers like LinkNet for increased precision.
Bypass layers are used to inform the decoder at each layer on how to aggregate features at multiple scales for better scene segmentation. Since the encoder layers downsample the image data in some layers, the encoder has to upsample the neural maps at each layer according to the features found in the encoder.
We have been arguing and showing for many years that Generative Ladder Networks like LinkNet provide the back-bone for categorization, precise localization with segmentation. Segmentation provides much refined localization in an image, and also provides better training examples for neural networks. The reason is that precise boundary group objects features together more efficiently than imprecise boundaries like bounding boxes. It is obvious to notice that a bounding box will contain a lot of pixel of the background or other categories. Training a neural network with such erroneous labels will decrease the power of categorization of the network, since the background information will confuse its training. We recommend NOT TO USE bounding box.
In the past the literature has been littered with approaches using bounding boxes, with very inefficient use of neural networks and even poor understanding of the way they work and can be used with parsimony. A list of sub-optimal methods is here: Yolo, SSD Single Shot Multi-Box Detector, R-CNN. A review and comparison of these inferior methods is here — we note that SSD is the only method that at least tries to use neural network as pyramids of scales to regress bounding boxes.
A list of reasons why these methods are sub-par:
The recent work from: Focal Loss for Dense Object Detection is more insightful, as it shows that Generative Ladder Networks can be seen as the basic framework that should drive future neural network designs for instance categorization, localization (see Note 1).
But how can we use networks like LinkNet to perform bounding box regression, key-point detections, and instance counting? This can be done by attaching subnetworks at the output of each each decoder layer as done hereand here. These subnetwork require minimal networks and small classifier to be fast and efficient. The design of these networks needs to be performed by experienced neural network architecture engineers. See our recent work here, where we show how one single neural network like LinkNet can perform all tasks mentioned.
Note 1: a recent tutorial on methods for localization, segmentation and Instance-level Visual Recognition also makes a point that model like LinkNetare a common framework for object detection. They call Generative Ladder Networks as: Feature Pyramid Network (FPN). They recognize Generative Ladder Networks have an intrinsic pyramid of scales built in by the encoder downsampling. They also recognize the decoder can upsample images to better localization, segmentation and more tasks.
Note 2: it is not a good idea to try to identify actions from a single image. Actions live in a video space. An image may give you an idea of an action, as it may identify a key frame that relates to an action, but it is not a substitute for the sequence learning require to accurately categorize actions. Do not use these techniques on single frames to categorize actions. You will not get accurate results. Use video-based neural network like CortexNet or similar.
Note 3: Segmentation labels are more laborious to obtain than bounding boxes. It is easier to label an image with rough bounding boxes that to precisely draw contour of all objects manually. This is one reason for the long life of inferior techniques like bounding boxes, dictated by the availability of more and large datasets with bounding boxes. But there are recent techniques that can help segmenting images, albeit maybe not as precisely as human labeling, but that can produce at least a first pass in segmenting a large number of image automatically. See this work (Learning Features by Watching Objects Move) and this as references.
Note 4: The encoder network for Generative Ladder Networks needs to be efficiently designed for realistic performance in real applications. One cannot use a segmentation neural network that takes 1 second to process one frame. Yet most results in the literature are focused on obtaining the best accuracy_only. We argue the best metric is _accuracy/inference time as reported here. This was the key design for our eNet and LinkNet. Several paper still use VGG as input network, which is the most inefficient model to date.
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…