Data that bundles together, is learned together
early days
It was the winter 1998 and I have just moved to Baltimore from Italy. I joined prof. Ernst Niebur at the Mind Brain Institute, Johns Hopkins University. At the time I was fascinated by the neuroscience of vision, and was trying to learn from neuroscience book how the brain works, how it makes sense of the stream of sensory information. One concept that was absolutely nebulous was how a brain would “learn”, or connect the sensory stream data to actionable insights. “Hebbian learning” kept coming up — a learning theory in neuroscience stating that “neurons that fire together, wire together”.
Fast forward to 2004, the book “On Intelligence” by Jeff Hawkins & Sandra Blakeslee was really exciting to me. Mostly because it brought back up the energy and hope I had back in 1998, while at Johns Hopkins. The hope was that by studying and trying to replicate the brain, one could finally figure out how it works, how it learns.
In the book, Hebbian learning and repeated cortical columns were concepts that struck with me. I was working on artificial spiking neural networks and the concept of neurons firing together to make visual filters was not reading material anymore, was something I built and could measure and play with. This is unlike real neurons, that are much harder to “play” and “measure” given they are embedded in large networks and in a complex biochemical environment.
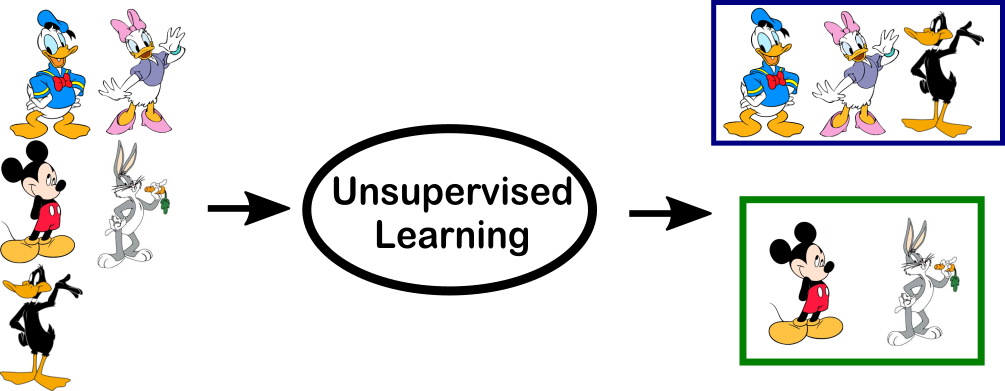
clustering
Yet it took me until 2012 to have a revelation about Hebbian learning . I was then starting to really work on machine learning using Torch7 and Lua, and thought that we could implement the concept of grouping together neurons that had similar outputs. For example filters that were responding to the same stimulus could be averaged together and combined. This was the idea behind clustering-learning that we developed and tested.
Then some years went by, and I was still trying to understand how one would be able to build a more complex brain. The trend in the year 2010–2020 was to build custom neural networks for each and every possibly application. One would get a dataset, inspect samples, craft a neural network architecture, then a cost function, and then train and modify parameters until time / resources / will would run out. After a few times of doing this, it all became very dull and almost pointless. Yes you can solve some problems if you have a fixed dataset of input-output relationships, but what if the dataset changed? What if the task changed, or a new category or new task was added? It would all fall apart!
I thought this was a betrayal of the paradigm “learning from data”
I started thinking for years about how one could learn complex tasks without forgetting the previous ones, and in a way that allowed to hierarchically build upon the knowledge discovered at earlier steps. In other word, a model that can support continual-learning and life-long learning, and that would require less or no tweaking of parameters — or at least change sporadically.
multi-modal
Today Hebbian learning came back once again to help me wrap my mind on a new brain and learning model. We spent a decade using machine-learning in isolation: image to text, text to text, text to image, sound to text, etc. But in our world all of possible sensory modality come to play together into a cohesive understanding of the world around us. A bird, for example, is not represented just by one image, it is video, it is motion, it is sound, it is all of these together! Imagine a waterfall: same thing! One image of a waterfall would not really represent what it is! It would look like a static object, lifeless, soundless. Not the roaring magnificence that one can perceive with human sense s— and image what we could do with even more sensory modalities!
multi-modal learning is key
The interesting thing of learning multiple modalities at once (multi-modal learning) is that you do not necessarily need a dataset! Modalities signal together when something occurs. For example when your foot hits the ground while walking, the event produces sound. These are signal that “fire together”, so maybe it would be appropriate to “wire them together”, what do you think?
You may ask now: what is an “event”? I use that word here because in the example of your foot hitting the ground and producing a sound I can remind you of a physical every-day reality. To you that sound is an “event”, but in reality we can group signal together even if they are not singular points in time, like for example the sound of the waterfall, which is continuous.
If we can find a space where different modalities could be compared and organized together, that would surely form a sound foundation of knowledge that is hierarchical and connected. We call this step “embedding” of modalities. It means that for every multi-modal group of signal, we create a numerical representation (say 512 numbers) that represent the “ensemble” of modalities together. Individual modalities can still be sensed independently and compressed with neural networks, and successively are projected into the same embedding space so they can be grouped and compared.
assembling knowledge
From the embedding space, we can now perform a critical learning step: we can force modalities that occur together to have the same representation, the same 512 numbers. We can do this training the embedding space to push events that happen together closer, and push apart events that are uncorrelated. Sounds familiar?
Well today, this modality, called contrastive-learning, has been a prevalent way of training a new class of neural networks and a more complex set of data. This training modality is the core of Stable Diffusion text to image models (example below).

https://github.com/CompVis/stable-diffusion
The goal of this blog post is to possibly convince you that we need to do more of this! We need to learn more modalities than just text and images, and combine them together into a singular embedding space. To me that new embedding space is a bit like a mini-cortex, a mini-brain, where attention-based cortical columns can make sense of the complex interaction of signals arising from life and the environment around us.
For example, think of PDF documents, fliers, brochures, medical data—what do they have in common? They aggregate text, images, videos, tables, time-series data into single documents: they co-occur together, so if we projected to the embedding space and group them, we will build hierarchical knowledge of dependent data.
Now imagine we took all the movies or videos on youtube. Same thing: we can use their text subtitles, text description, video and sound and learn an embedding space that will cluster events together. We can now sure learn what a waterfall is, because we will see it move, hear its sound.
Now Hebbian learning sounds quite interesting because it could be the foundation of the next “Google”. If we can connect knowledge now just by text, like the Web 1.0–2.0, but by multiple modalities, we would then have a much more sophisticated and powerful semantic search. After all what is a word? It is just a representation (and embedding) of a real concept, a mixture of sensory signals, a qualia.
And the revelation of this post, which I stumbled upon by searching a way to replicate brains over the years, is also surfacing from many colleagues in the area with the same life goals: building a clone of the human brain. See: HuggingFaces and Jira for example. I think you may recognize some of the underlying ideas.
advantages
What could we do with this? After all it seems like I am only giving you a recipe to group things together… what comes next is “prediction”. A theory of the brain by Friston suggests that the brain is predicting future events all the time, and ignores most events that can be predicted, and focuses attention on what cannot be predicted.
Imagine you see a restaurant room full of tables: nothing much to report. But now you see a table standing with only two legs. You would be “surprised”! Because that is not common! In your knowledge all tables that stand have 4 or at least 3 legs!
Now you see: if we have grouped data together that is common, we would have an easier time to figure out what is uncommon. Machine-learning today struggles with anomaly detection tasks like this.
In addition embedding multi-modal information should have a big advantage in continual-learning. That is because as we had more data, it will have to be embedded into the same space, in a way averaging over concepts that we have learned before. And in a continual learning scenario, we would continue to build a knowledge graph that need to be consistent with reality, and thus robust to new datapoints. All this has to be proven, it is a conjecture right now.
The other immense advantage of multi-modal learning is that it can be trained largely unsupervised! Meaning we do not need to curate and provide a large set of examples. We still need data, yes, but all we need is multi-modal data, not the labels. Training with contrastive learning techniques thus can relieves from the immense problem of creating an input/output dataset.
applications
With contrastive learning and a common embedding space, we can thus organize knowledge into a neural graph, as data from different modalities is connected and grouped into semantical concepts that can be queried. This is similar to building a language without a language: a language of the brain, made of codes and relative position of concepts. In this space distance is a metric of connectivity, similarly to what happens in natural language processing, where similar concepts group together (see below).
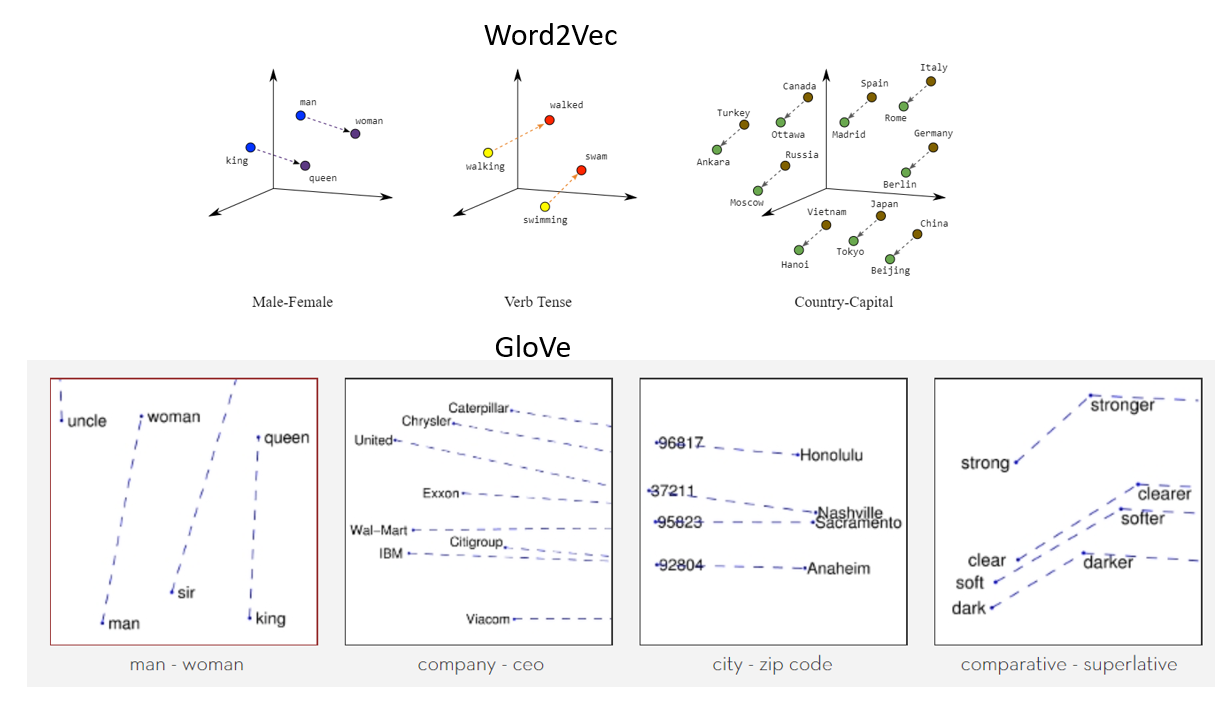
semantic grouping of words
Using this we can open to many potential applications:
- understanding complex relationship in complex multi-modal documents
- generating text, sounds, video, images
- organizing human knowledge and finding new connections between data
- connecting different areas of knowledge that are now loosely connected
- automatic discovery of knowledge
final
I hope these ideas have piqued your interest in artificial brains and neural networks and help you think of how we can do more with the massive amount of data we have, how to learn how to learn, how to grow a brain.
notes
- Hebbian learning is just a theory
- there could be multiple other ways to learn and scale
- https://medicalxpress.com/news/2018-11-neurons-dont-wire.html
about the author
I have more than 20 years of experience in neural networks in both hardware and software (a rare combination). About me: Medium, webpage, Scholar, LinkedIn.
If you found this article useful, please consider a donation to support more tutorials and blogs. Any contribution can make a difference!