Learning to see
How do humans learn to make sense of the world? How do we learn what is us and what is others? How do we learn about moving in space, manipulating objects, physics, imitating others?
It all starts with our senses, and one in particular: vision. Vision allows an entity to perceive the world from the distance, gathering a large amount of information per unit time. The other important sense is audition, but here we focus mostly on vision.

Gemini-Pro: “ a robot learning to see like a baby on a table with toys”
How do we learn to see?
When human babies are born, there is not enough data in their DNA to program all the cortical weights involved in vision. If we want to create an artificial vision system, we ought to take inspiration and guidance on the human visual system.
The human visual field covers a large spatial area, and there is a lot of information in the perceived visual scene. This is too much information, and there needs to be a mechanism to reduce it the minimum required for survival. Evolution had billions of years of trials and errors, and so the mammalian visual system is based on:
-
A blurry version of the entire visual field (peripheral vision)
-
A high resolution “focus area” that we can move around (fovea)
Instead of seeing everything in high-fidelity, we see a large visual portion with very low fidelity, and only a small portion in high resolution. Say we have a visual field that in a robotic camera would be 5000 x 3000 pixels. Peripheral vision could be 500 x 300 and the fovea could be, say, 300 x 300 pixels. These are just example numbers (for more, see this).
Humans have to move their eyes (and head) in order to get all the details of a scene. We produce “saccades”, or eye movements, which then give us “fixations”, portions of content in high-resolution. Multiple fixations in a sequence give us the appearance of a unified visual field, even when they are a discrete set augmented by a low-resolution wide view.
If we have to produce fixations, how do we figure out where to look next? How do babies know they need to look at people’s faces, for example, rather than moving leaves on a tree or just the ceiling? Looks like a chicken-in-the-egg problem. This means we will need some kind of visual attention, an algorithm that allow us to “scan” a scene for details, so that a complete picture can be created with a series of high-resolution fixations.
Attention
Somehow the visual scene needs to tell us where to look. This is called “bottom-up” attention, and it a combination of visual details which grab your visual attention and make you move your eyes toward:
-
Motion in the field of view
-
High contrast areas
-
Contrast in colors
All these visual features attract our attention, our bottom-up attention. This is not what we do when we are on a visual task, like looking for your keys at home. That is “top-down” attention. More on that later.
But back to the main question: who do we learn to see? We do not have an answer today. But we have to start somewhere. Let’s think about babies in their first week of life. At the beginning they do not even know where to look, their eyes cross and they cannot even focus.
Having some kind of bottom-up attention may be a way to pre-condition the visual system to be getting the right information, after all a robot (baby?) that only looks at the ceiling would not be useful or insightful. Possibly there is a built-in innate circuit for visual attention that we are born with.
Now, we can argue that bottom-up attention, coupled with the sense of audition, directs a baby to look at someone’s face. Babies start to recognize caregivers and smile within 6 weeks! Some aspects of face detection are even present at birth, possibly suggesting the presence of some kind of innate face-detector circuitry.
First steps
How does a baby learn what are familiar faces, positive and negative facial expressions? There needs to be a “reward” mechanism, something that can tell a baby that something is good or bad. Remember the baby’s brain does not know anything at first, and to the brain reward is just another signal. There has to be more, maybe this signal is wired so strongly to parts of the brain that it makes it react similarly to adults. Reacting newborn babies feeling pain, for example, have elevated hearth rates of cry. It seems some of the reward signals are hardwired to behavior, and for a reason: survival.
Recognizing the faces of friends and foes is important to newborn animals for survival, in the same way that it is important to recognize pain and discomfort.
Thinking about replicating vision in an artificial system, like robotic vision, the information we just reviewed is important and revealing:
- We need circuits to bootstrap vision, bottom-up visual attention
- Some kind of reward sensing: pain and pleasure, energy gain and loss
- Face detectors? Innate detectors? What is built in?
The capability of active visual perception (learning to see) develops when the following sequence of exemplary events occurs:
- Bottom-up attention produces proposals for fixations
- Looking at the right direction give us a reward (right fixations)
- The reward signal and looking in the right direction are correlated
- This correlation teaches us how to direct our sight and where we should pay attention to!
Examples are:
- A baby looks around and sees the mother’s face. Gets a pleasure reward from that. Correlates faces with positive or negative rewards.
- What else can stimulate a baby vision?
- Can predictive abilities give a reward signal? For example a baby can look at something until it learns a “model” of that something, and if so, learn to ignore it. As such a pleasure signal is given while learning / not knowing the model
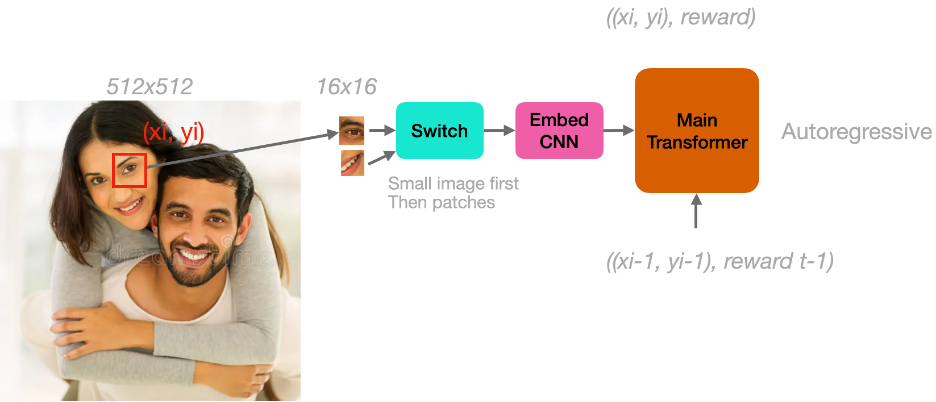
a sketch of a model: Mix-Match
Training a neural network model of vision
In order to replicate foveated visual systems in a robot, we need the following components:
- A bottom-up visual attention model. This can be a pre-trained CNN + a motion detector, for examples this code.
- Some hard-wired reward: seeing a face, orienting gaze and head toward sources of pleasure. We need to hard wire some of this in the model, for example it can be a separate add-on word that is added to the inputs. Adding it to the inputs will allow the network to learn to bypass it
- A multi-modal Mix-Match Transformer model to learn correlation of right fixations and positive rewards (right, +rewards) and prediction (looking there may give me a +reward)
This can bootstrap the learning or more (right, +reward) thus enabling to learn additional reward rules that foster more and more complex capabilities.
about the author
I have more than 20 years of experience in neural networks in both hardware and software (a rare combination). About me: Medium, webpage, Scholar, LinkedIn.
If you found this article useful, please consider a donation to support more tutorials and blogs. Any contribution can make a difference!