Navigating the Unsupervised Learning Landscape
Unsupervised learning is the Holy Grail of Deep Learning. The goal of unsupervised learning is to create general systems that can be trained with little data. Very little data.
Today Deep Learning models are trained on large supervised datasets.Meaning that for each data, there is a corresponding label. In the case of the popular ImageNet dataset, there are 1M images labeled by humans. 1000 images for each of the 1000 classes. It can take some effort to create such dataset, many months of work. Imagine now creating a dataset with 1M classes. Imagine having to label each frame of a video dataset, with 100M frames. This is not scalable.
Now, think about how you got trained when you were very little. Yes you got some supervision, but when your parents told you that is a “cat” they would not tell you “cat” every split second you were looking at a cat for the rest of your life! That is what supervised learning is today: I tell you over and over what a “cat” is, maybe 1M times. Then your Deep Learning model gets it.
Ideally, we would like to have a model that behaves more like our brain. That needs just a few labels here and there to make sense of the multitude of classes of the world. And with classes I mean objects classes, action classes, environment classes, object parts classes, and the list goes on and on.
As you will see in this review, the most successful models are the ones that predict future representation of a video. One issue that many of these techniques have, and are trying to resolve, is that training for a good overall representation needs to be performed on videos, rather than still images. This is the only way to apply the learned representation to real-life tasks.
General concepts
The main goal of unsupervised learning research is to pre-train a model (called “discriminator” or “encoder”) network to be used for other tasks. The encoder features should be general enough to be used in a categorization tasks: for example to train on ImageNet and provide good results, as close as possible as supervised models.
Up to date, supervised models always perform better than unsupervised pre-trained models. That is because the supervision allows to model to better encode the characteristics of the dataset. But supervision can also be decremental if the model is then applied to other tasks. In this regards, the hope is that unsupervised training can provide more general features for learning to perform any tasks.
If real-life applications are the targets, as in autonomous driving, action recognition, object detection and recognition in live feeds, then these algorithms need to be trained on video data.
Auto-encoders
Originated largely from Bruno Olshausen and David Field in 1996. This paper showed that coding theory can be applied to the receptive field in the visual cortex. They showed that the primary visual vortex (V1) in our brain uses principles of sparsity to create a minimal set of base functions that can be also used to reconstruct the input image.
A great review is here
Yann LeCun group also worked a lot in this area. In this page you can see a great animation of how sparse filters V1-like are learned.
Stacked-auto encoders are also used, by repeating the process of traininggreedily layer by layer.
Auto-encoders methods are also called “direct-mapping” methods.
Auto-encoders / sparse-coding / stacked auto-encoders advantages and disadvantages
Advantages:
- simple technique: reconstruct input
- multiple layer can be stacked
- intuitive and based on neuroscience research
Disadvantages:
- each layer is trained greedily
- no global optimization
- does not match performance of supervised learning
- multiple layer ineffective
- reconstruction of input may not be ideal metric for learning a general-purpose representation
Clustering Learning
One technique uses k-means clustering to learn filters at multiple layers.
Our group named this technique: Clustering Learning, Clustering Connections and Convolutional Clustering, which very recently achieved very good results on the popular STL-10 unsupervised dataset.
Our work in this area was developed independently to the work of Adam Coates and Andrew Ng.
Restricted Boltzmann machines (RBMs), deep Boltzmann machines (DBMs), Deep belief networks (DBNs) have been notoriously hard to train because of the numerical difficulties of solving their partition function. As such they have not been used widely to solve problems.
Clustering learning advantages and disadvantages:
Advantages:
- simple technique: cluster similar outputs
- multiple layer can be stacked
- intuitive and based on neuroscience research
Disadvantages:
- each layer is trained greedily
- no global optimization
- in some cases matches performance of supervised learning
- multiple layer increasingly ineffective == diminishing returns
Generative models
Generative models try to create a categorization (discriminator or encoder) network and a model that generates images (generative model) at the same time. This method originated from the pioneering work of Ian Goodfellow and Yoshua Bengio. Here is a great and recent summary of GAN by Ian.
The generative adversarial model by Alec Radford, Luke Metz, Soumith Chintala named DCGAN instantiates one such model that got really awesome results.
A good explanation of this model is here. See this system diagram:
The DCGAN discriminator is designed to tell if an input image is real, or coming from the dataset, or fake, coming from the generator. The generator takes a random noise vector (say 1024 values) at the input and generates an image.
In the DCGAN, the generator network is:
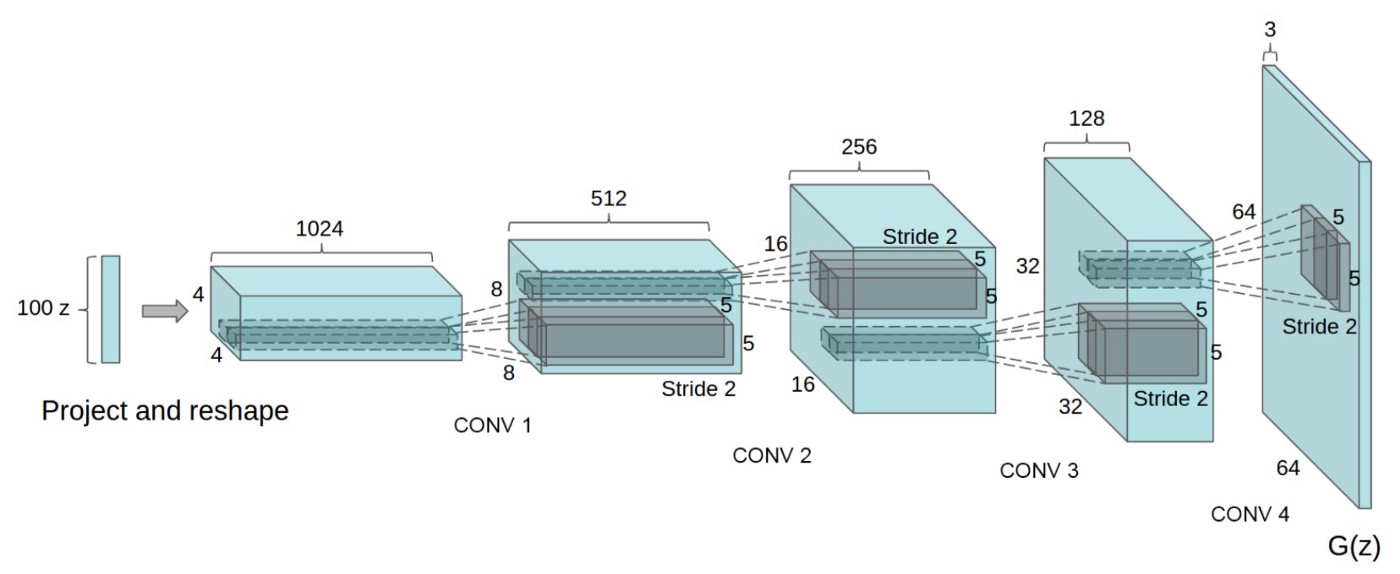
while the discriminator is a standard neural network. See code below for details.
The key is to train both networks in parallel while not completely overfitting and thus copying the dataset. The learned features need to generalize to unseen examples, so learning the dataset would not be of use.
Training code of DCGAN in Torch7 is also provided, which allow for great experimentation.
After both generator and discriminator network are trained, one can use both. The main goal was to train a nice discriminator network to be used for other tasks, for example categorization on other datasets. The generator can be used to generate images out of random vectors. These images have very interesting properties. First of all, they offer smooth transitions from the input space. See an example here, where they show the images produced by moving between 9 random input vectors:

Also the input vector space offers mathematical properties, showing the learned features are organized by similarity:
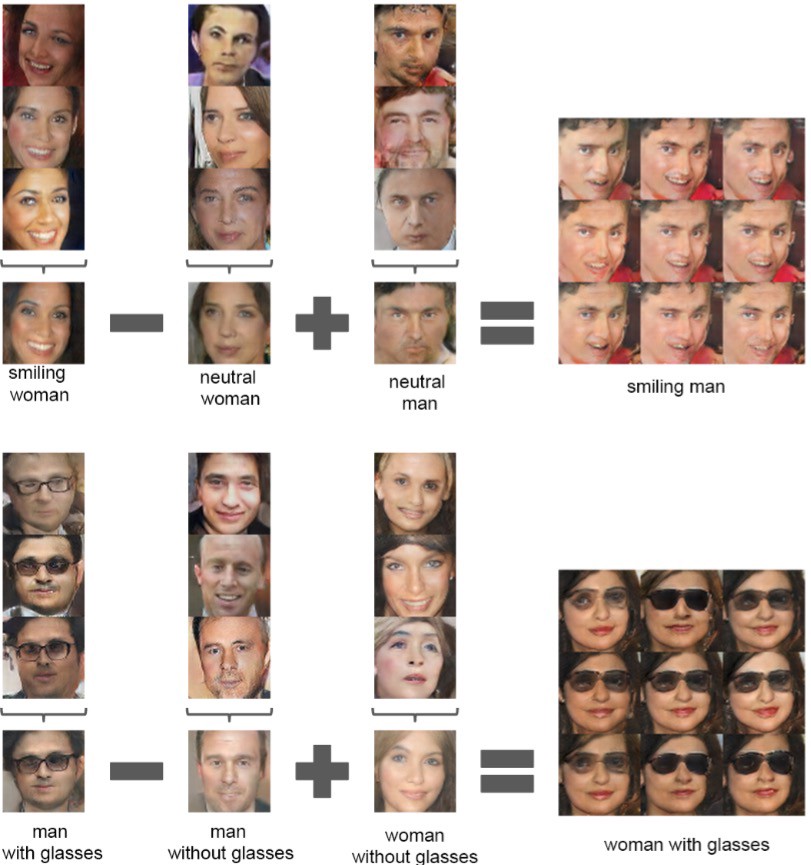
The smooth space learned by the generator suggests that the discriminator also has similar properties, making it a great general feature extractor for encoding images. This should help the typical problem of CNN trained in discontinuous image datasets, where adversarial noise makes them fail.
A recent update to the GAN training, provided a 21% error rate on CIFAR-10 with only 1000 labeled samples.
A recent paper on infoGAN was able to produce very sharp images with image features that can be dis-entangled and have more interesting meaning. They, however, did not report the performance of the learned features in a task or dataset for comparison.
Interesting summary on generative models are also here and here.
Another very interesting example is given here where the authors use generative adversarial training to learn to produce images out of textual descriptions. See this example:

What I appreciate the most about this work is that the network is using the textual description as input to the generator, as opposed to random vectors, and can thus control accurately the output of the generator. A picture of the network model is here:

Generative adversarial model advantages and disadvantages
Advantages:
- global training of entire network
- simple to code and implement
Disadvantages:
- hard to train, conversion problems
- in some cases matches performance of supervised learning
- need to prove usability of representation (a problem of ALL unsupervised algorithms)
Learn-from-data models
These models learn directly from unlabeled data, by devising unsupervised learning tasks that do not require labels, and learning aims at solving the task.
Unsupervised learning of visual representations by solving jigsaw puzzles is a clever trick. The author break the image into a puzzle and train a deep neural network to solve the puzzle. The resulting network has one of the highest performance of pre-trained networks.
Unsupervised learning of visual representations from image patches and locality is also a clever trick. Here they take two patches of the same image closely located. These patches are statistically of the same object. A third patch is taken from a random picture and location, statistically not of the same object as the other 2 patches. Then a deep neural network is trained to discriminate between 2 patches of same object or different objects. The resulting network has one of the highest performance of pre-trained networks.
Unsupervised learning of visual representations from stereo image reconstructions takes a stereo image, say the left frame, and reconstruct the right frame. Albeit this work was not aimed at unsupervised learning, it can be! This method also generates interesting 3D movies form stills.
Unsupervised Learning of Visual Representations using surrogate categoriesuses patches of images to create a very large number of surrogate classes. These image patches are then augmented, and then used to train a supervised network based on the augmented surrogate classes. This gives one of the best results in unsupervised feature learning.
Unsupervised Learning of Visual Representations using Videos uses an encoder-decoder LSTM pair. The encoder LSTM runs through a sequence of video frames to generate an internal representation. This representation is then decoded through another LSTM to produce a target sequence. To make this unsupervised, one way is to predict the same sequence as the input. Another way is to predict future frames.
Another paper (MIT: Vondrick, Torralba) using videos with very compelling results is here. The great idea behind this work is to predict the representation of future frames from a video input. This is an elegant approach. The model used is here:
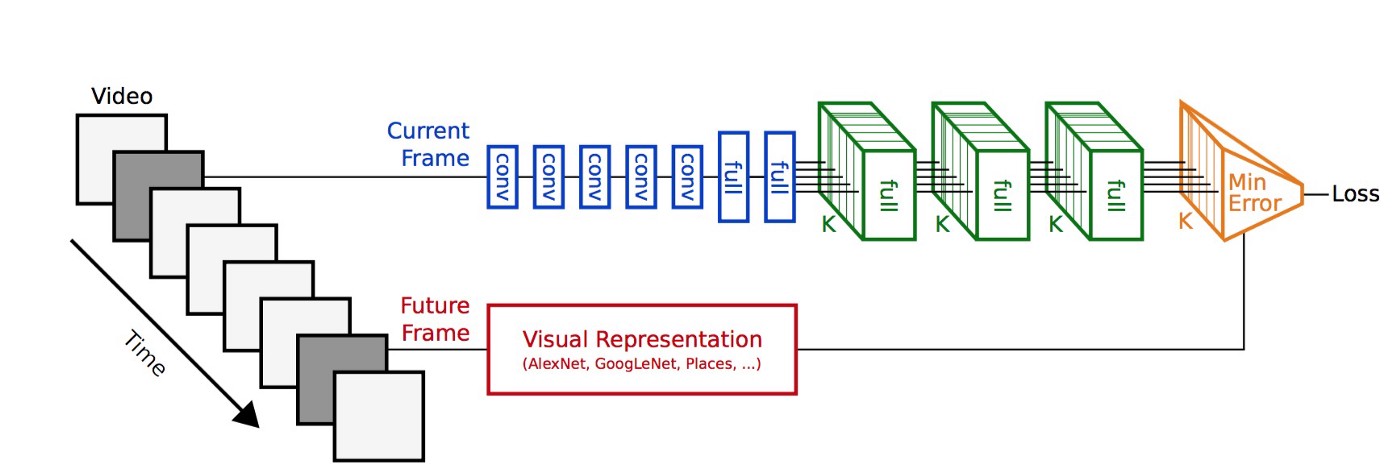
One problem of this technique is that a standard neural network trained on static frames is used to interpret a video. Such networks does not learn the temporal dynamics of video and the smooth transformation of objects moving in space. Thus we argue this network is ill-suited to predict future representations in video.
To overcome this issue, our group is creating a large video dataset eVDScreated to train new network models (recursive and feed-back) directly on video data.
Predictive networks
Predictive deep neural networks are models that are designed to predict future representations of the future.
PredNet is a network designed to predict future frames in video. See great examples here: https://coxlab.github.io/prednet/
PredNet is a very clever neural network model that in our opinion will have a major role in the future of neural networks. PredNet learns a neural representation that extends beyond the single frames of supervised CNN.
PredNet combine bio-inspired bi-directional [models of the human brain] (https://papers.nips.cc/paper/1083-unsupervised-pixel-prediction.pdf). It uses predictive coding and using [feedback connections in neural models] (http://arxiv.org/abs/1608.03425). This is the PredNet module and example of 2 stacked layer:
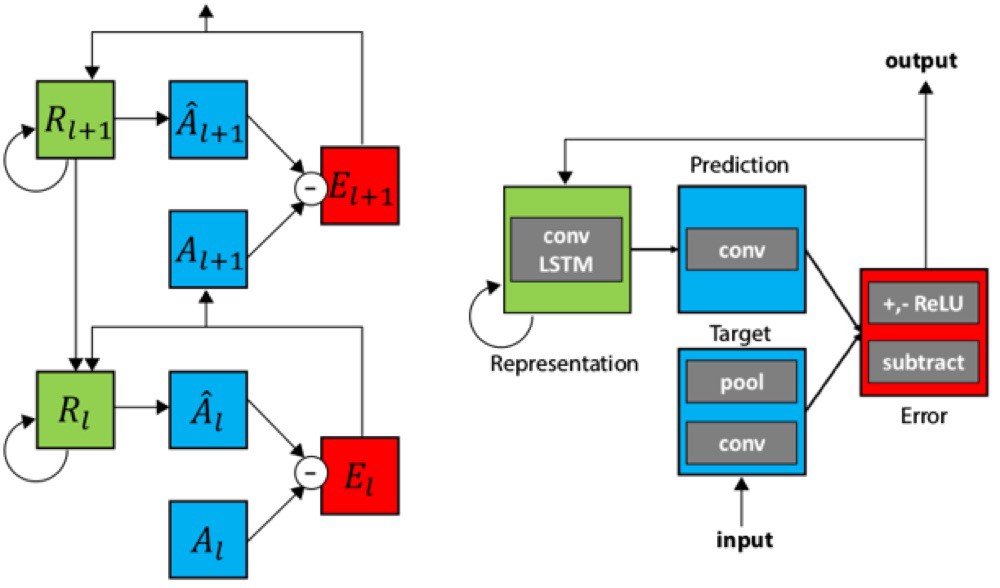
This model also has the following advantages:
- uses unlabeled data to train!
- embedded loss function computing error at each layer
- ability to perform online-learning by monitoring the error signal: when it is not able to predict an output, it knows it needs to learn it
One issue with PredNet is that predicting the future input frame is a relatively easy task some simple motion-based filters at the first layer. In our experiments PredNet this learns to do a great job at re-constructing an input frame, but higher layer do not learn a good representations. In our experiments, higher layer in fact are not able to solve simple tasks like categorization.
Predicting the future frame is in fact not necessary. What we would like to do is to predict future representations of next frames, just like Carl Vondrick does.
A very interesting model is the PVM from BrainCorporation. This model aims at capturing bidirectional and recurrent connections in the brain, and also provide local layer-wise training.
This model is very interesting because it offers connectivity similar to new network models (recursive and feed-back connections). These connections provide temporal information and generative abilities.
It is also interesting because it can be trained locally, with each PVM unit trying to predict its future output, and adjusting only local weights appropriately. This is quite different from the way deep neural network are trained today: back-propagating errors throughput the entire network.
The PVM unit is given below. It has inputs from multiple lower layers, to which it also provides feedback, and lateral connections. The feedback is time-delayed to form recurrent loops.
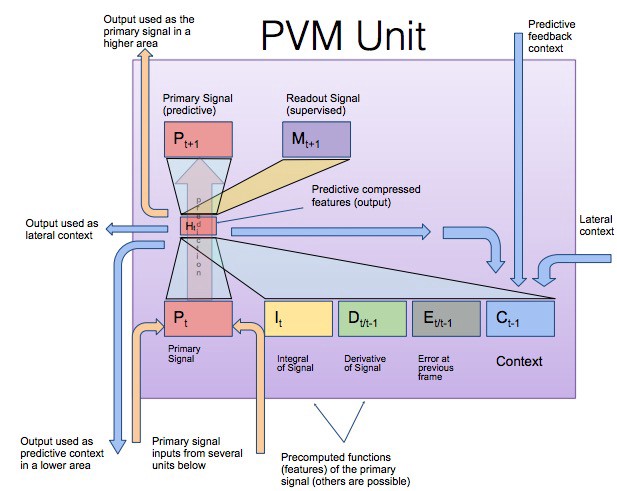
More details about the PVM system are given here.
Learning features by looking at objects move
This recent paper (April 2017) trains unsupervised models by looking at motion of objects in videos. Motion is extracted as optical flow, and used as a segmentation mask for moving objects. Even though optical flow signal does not give anywhere close to a good segmentation mask, the averaging effect of training on a large data allow the resulting network to do a good job. Examples below.
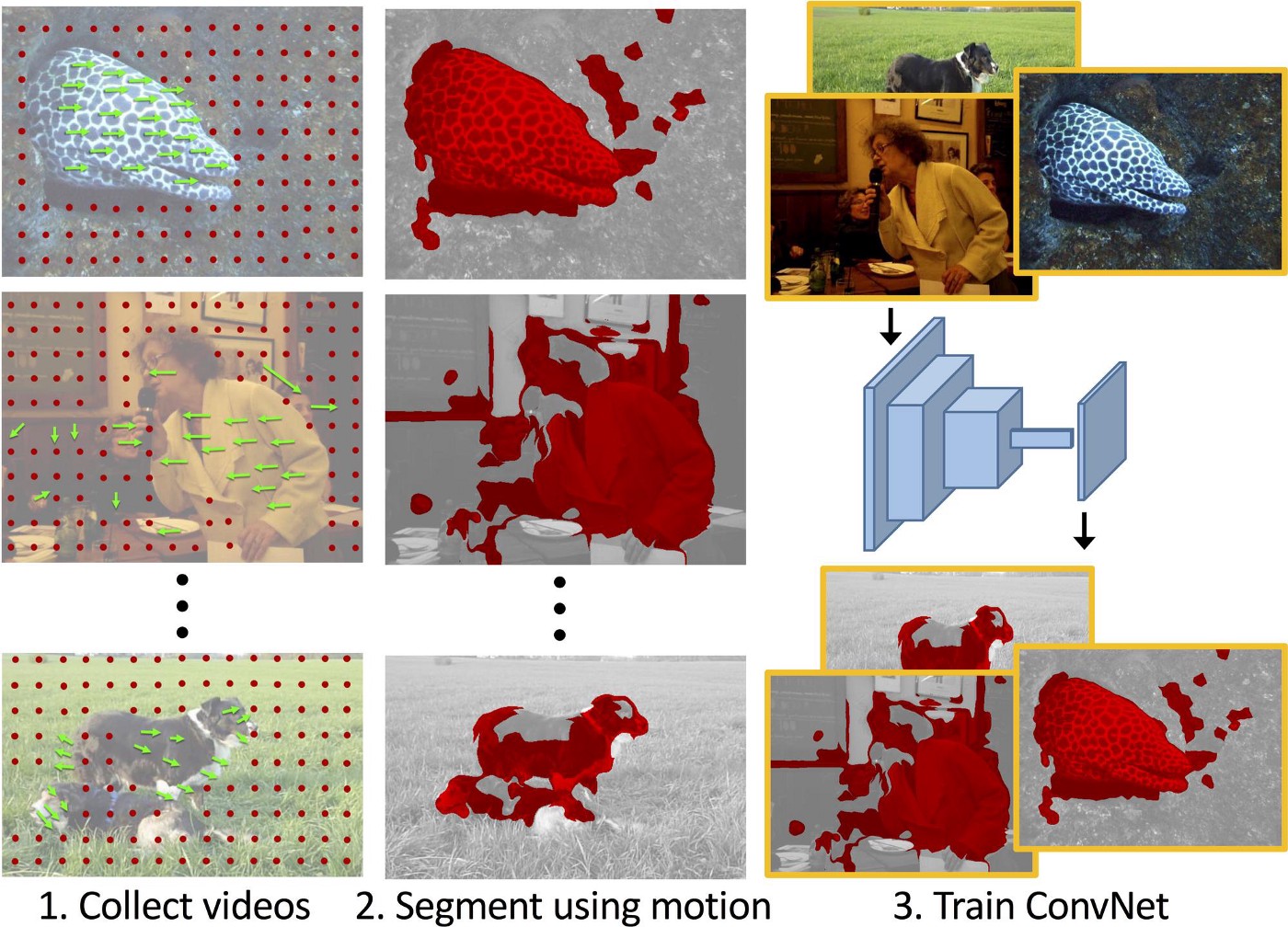
This work is very exciting because it is follows neuroscience theories of how the visual cortex develops by learning to segment moving objects.
The future
Is your to make.
Unsupervised training is very much an open topic, where you can make a large contribution by:
- creating a new unsupervised task to train networks, e.g.: solve a puzzle, compare image patches, generate images, …)
- thinking of tasks that create great unsupervised features, e.g.: what is object and what is background, same on stereo images, same on video frames ~= similar to how our human visual system develops
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…