Snowflake
The most efficient deep neural network accelerator — FWDNXT.com
by Vinayak Gokhale, Aliasger Zaidy, Andre Chang, Eugenio Culurciello
Deep convolutional neural networks (CNNs) are the deep learning model of choice for performing object detection, classification, semantic segmentation and natural language processing tasks. CNNs require billions of operations to process a frame. This computational complexity, combined with the inherent parallelism of the convolution operation make CNNs an excellent target for custom accelerators. However, when optimizing for different CNN hierarchies and data access patterns, it is difficult for custom accelerators to achieve close to 100% computational efficiency. Our team at Purdue University has designed Snowflake, a scalable and efficient accelerator that is agnostic to CNN workloads, and was designed with the primary goal of optimizing computational efficiency.
Snowflake is able to achieve a computational efficiency of over 91% on entire modern CNN models, and 99% on some individual layers. Implemented on a Xilinx Zynq XC7Z045 SoC is capable of achieving a peak throughput of 128 G-ops/s and a measured throughput of 100 frames per second and 120 G- ops/s on the AlexNet CNN model, 36 frames per second and 116 G-ops/s on the GoogLeNet CNN model and 17 frames per second and 122G-ops/s on the ResNet-50 CNN model. To the best of our knowledge, Snowflake is the only implemented system capable of achieving over 91% efficiency on modern CNNs and the only implemented system with GoogLeNet and ResNet as part of the benchmark suite.
Here are some of Snowflake results and performance:
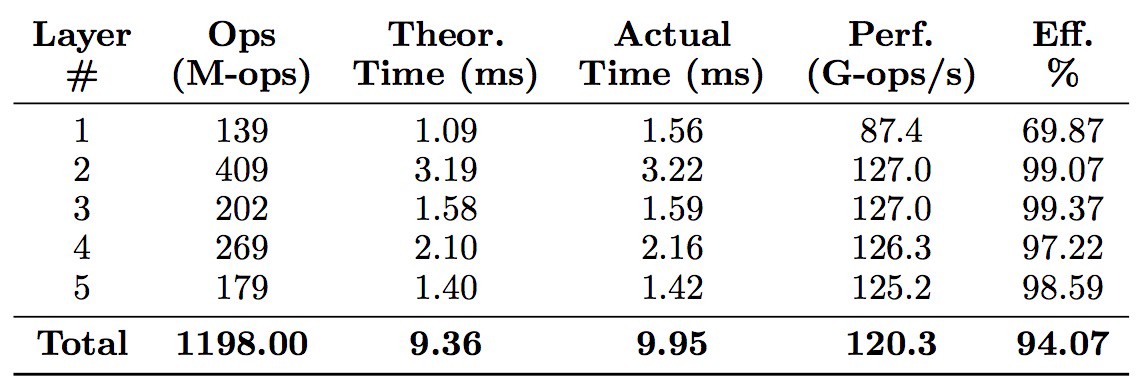
Performance on AlexNet
Average performance on AlexNet is above 94%.
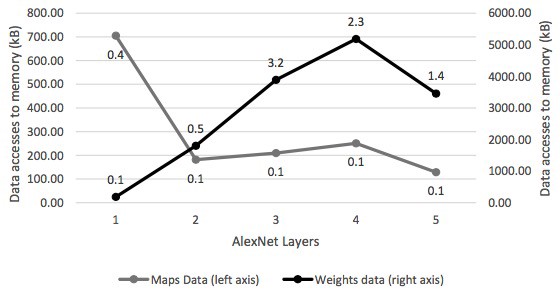
Data movements of maps and neural network weights by Snowflake while computing AlexNet.
The figure above shows the size of weights and maps data moved to and from memory by the Snowflake system. The left axis is for the maps and the right axis is for the weights. The numbers written above each point are the bandwidth in GB/s. AlexNet requires an average bandwidth of 1.53 GB/s.
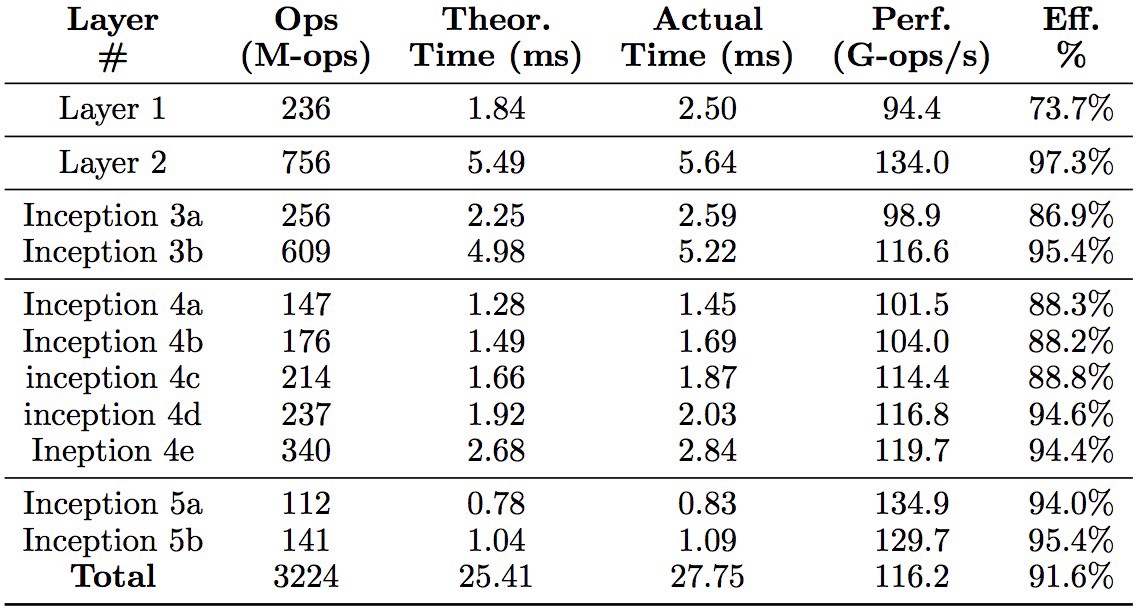
Performance on GoogleNet
Average performance on GoogleNet is above 91%.
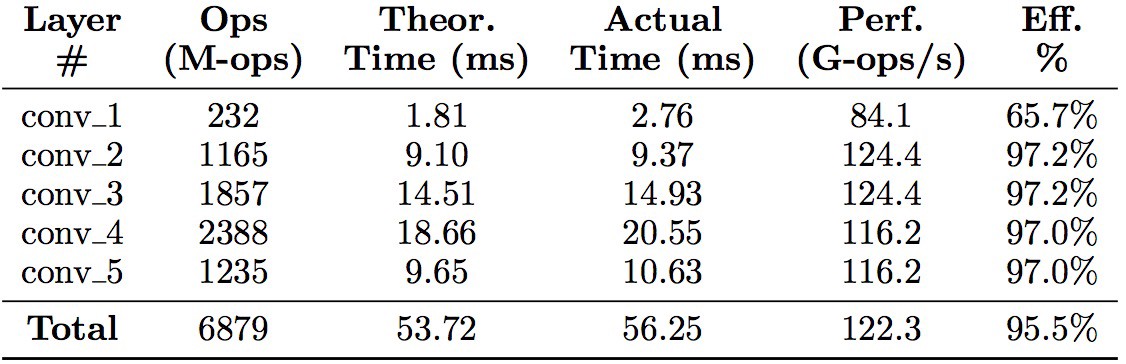
Performance on ResNet-50
Average performance on ResNet-50 is above 95%.
Below is a comparison with recent literature. Snowflake is the most efficient deep neural network accelerator to date.

A comparison of throughput and efficiency across recent works in literature
We also report snowflake arithmetic intensity in the figure below. This is the number of operations performed on a byte of data. As you can see all neural network models tested perform at the maximum (roofline) efficiency of the device. On the other hand linear layers have very little data re-use and are limited by memory bandwidth constraints.
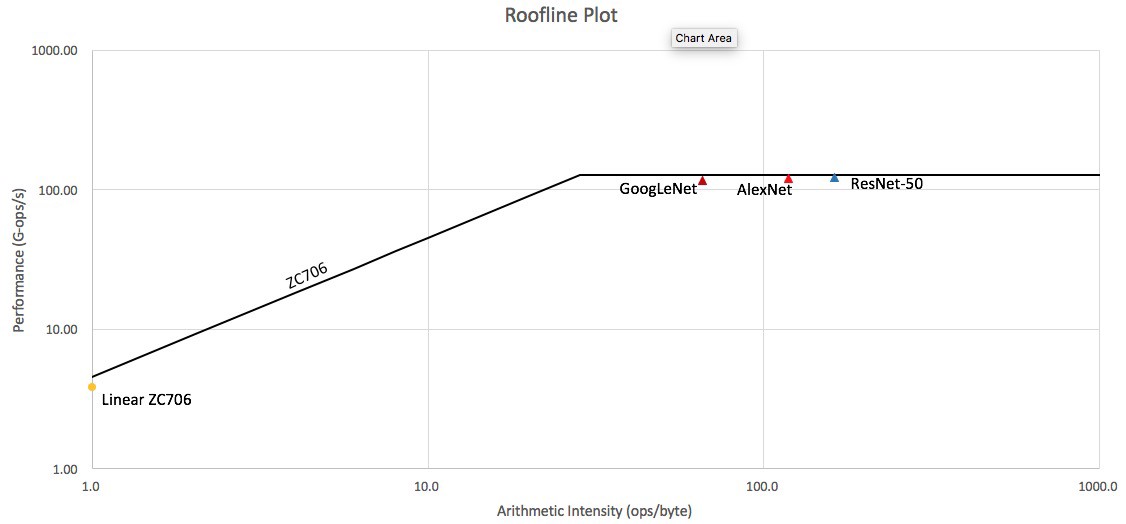
Snowflake was designed for scalability and we will soon report number for larger systems.
See below for a comparison with Google TPU also, where Snowflake SoC is again a winner in performance per power. Notice in this comparison we kept very optimistic number for the TPU and GPU, which performs much lower than 100% utilization when running models it is not optimized for (GoogleNet).
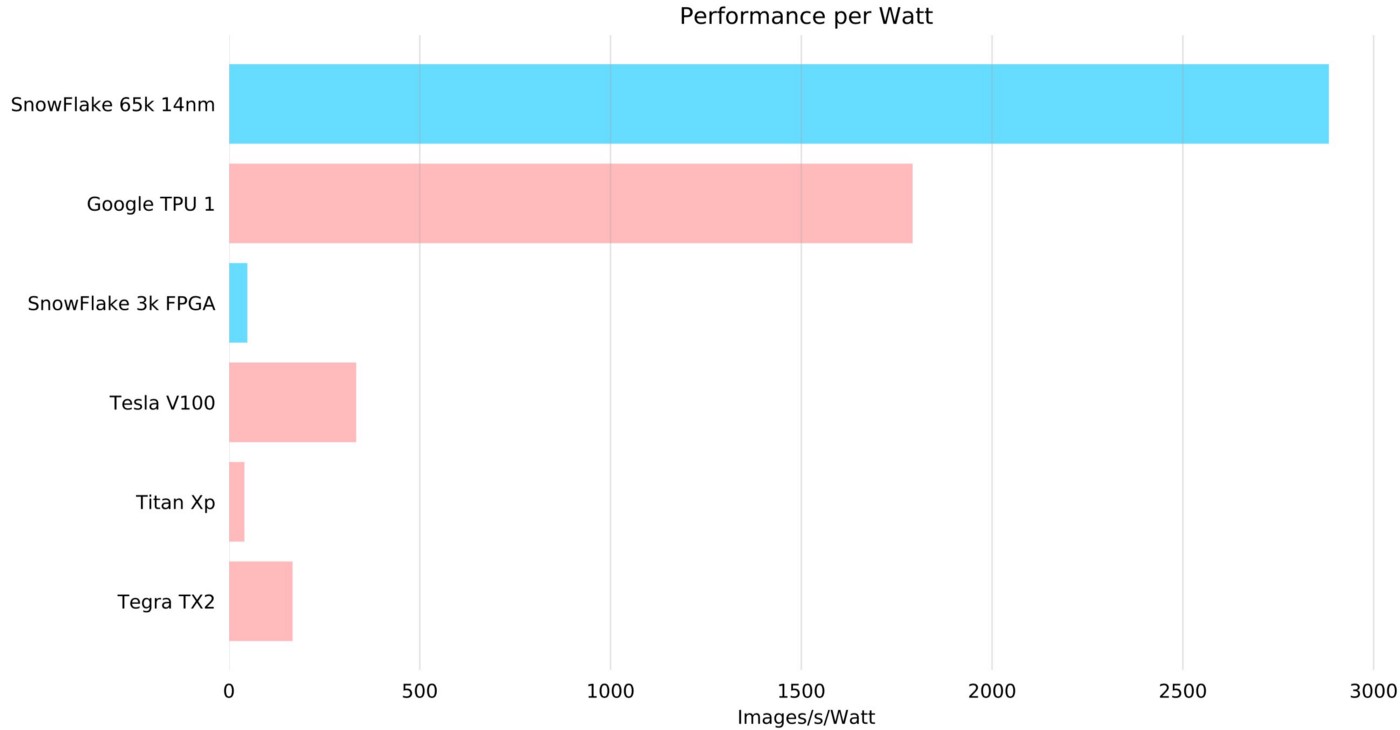
Notice also that a Snowflake 3k FPGA system will have the same computational power of the latest NVIDIA Titan Xp GPU. This means you can carry a GPU like that in your pocket!

Snowflake is the most efficient deep neural network processor in the world.
Here is a lineup of Snowflake products, and a video demonstration:
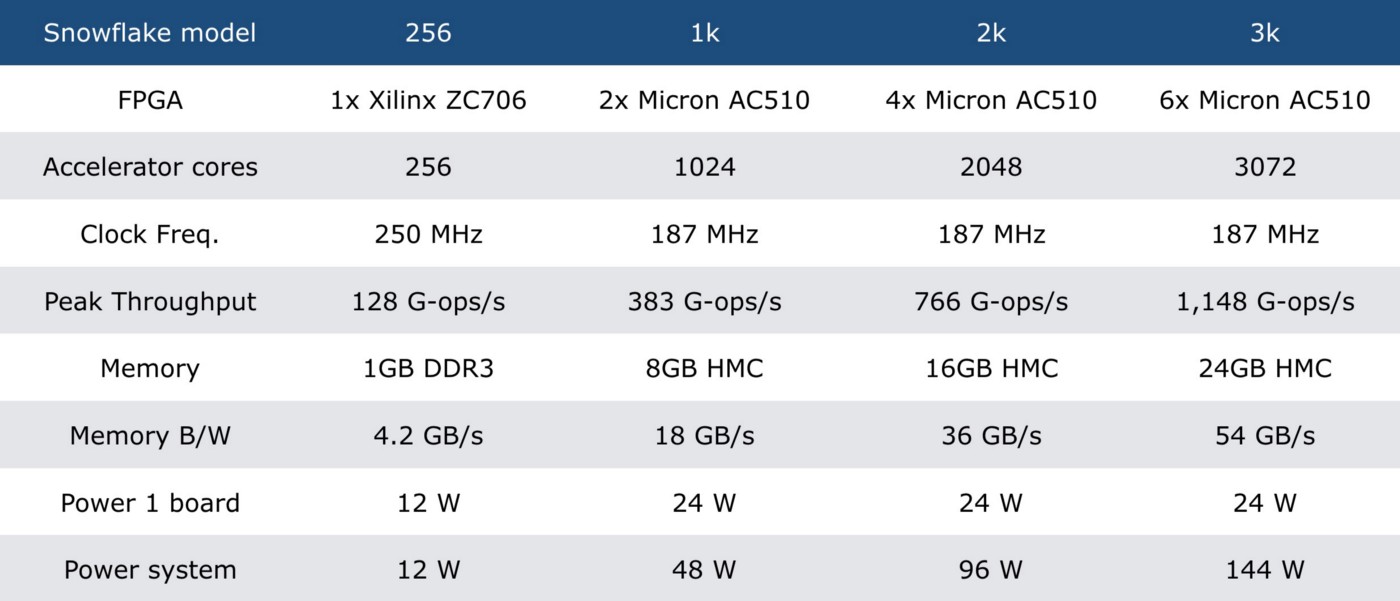
Snowflakes lineup
A video of Snowflake 3k in action
Note about comparisons: we used the highest available performance numbers and lowest power numbers from these sources:
Snowflake paper: https://arxiv.org/abs/1708.02579
Google TPU: https://arxiv.org/abs/1704.04760
For NVIDIA V100 we used: https://www.nvidia.com/en-us/data-center/tesla-v100/, power 300W, Deep Learning performance: 120 Tflops
For NVIDIA Titan Xp: https://www.nvidia.com/en-us/geforce/products/10series/titan-xp/, power 250 W, single precision FP32 performance: 12.1 Tflops — FP16 performs worse than FP32 so we have not used it
For NVIDIA Tegra X2: https://en.wikipedia.org/wiki/Tegra#Tegra_X2, power: 7.5 W, performance: 1.5 Tflops