Memory, attention, sequences
We have seen the rise and success of categorization neural networks. The next big step in neural network is to make sense of complex spatio-temporal data coming from observing and interacting with the real world. We talked before about the new wave of neural networks that operate in this space.
But how can we use these network to learn complex tasks in the real world? For example, how can I tell my advanced vacuum cleaning robot: “Roomby: you forgot to vacuum the spot under the red couch in the living room!” and get an proper response?
For this to happen, we need to parse spatio-temporal information with attention mechanism, so we can understand complex instruction and how they relate to our environment.
Let us consider a couple of example applications: summarization of text or video. Consider this text:
“A woman in a blue dress was approached by a woman in a white dress. She cut a few slices of an apple. She then gave a slice to the woman in blue.”
In order to answer to the question: “who offered a slice of apple?” we need to focus on “apple”, “apple owner”, “give” words and concepts. The rest of the story is not relevant. These part of the story need our attention__.
A similar situation occurs in video summarization, where a long video can be summarized in a small set of sequences of frames where important actions are performed, and which again require our attention. Imagine you are looking for the car keys, or your shoes, you would focus on different part of the video, and the scene. For each action and for each goal, we need attention to focus on the important data, and ignore the rest.

Example of video summarization
Well if you think about it, summarization and a focused set of data is important for every temporal sequence, be it translation of a document, or action recognition in video, or the combination of a sentence description of a task and the execution in an environment.
all these tasks need to reduce the data to focal set, and pay attention to the set in order to provide an answer or action
Attention is then one of the most important components of neural networks adept to understand sequences, be it a video sequence, an action sequence in real life, or a sequence of inputs, like voice or text or any other data. It is no wonder that our brain implements attention at many levels, in order to selectonly the important information to process, and eliminate the overwhelming amount of background information that is not needed for the task at hand.
A great review of attention in neural network is given here. I report here some important diagrams as a reference:
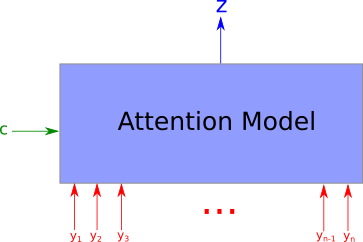
An attention model is a method that takes n arguments y_1 … y_n and a context c. It returns a vector z which is the summary of the y_i focusing on the information linked to context c. More formally, it returns a weighted arithmetic mean of the y_i and the weights are chosen according the relevance of each y_i given the context c.
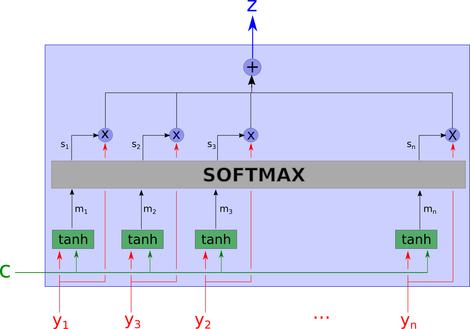
Implementation of the attention model. Notice that m_i = tanh(W1 c + W2 y_i), meaning that both y_i and c are linearly combined.
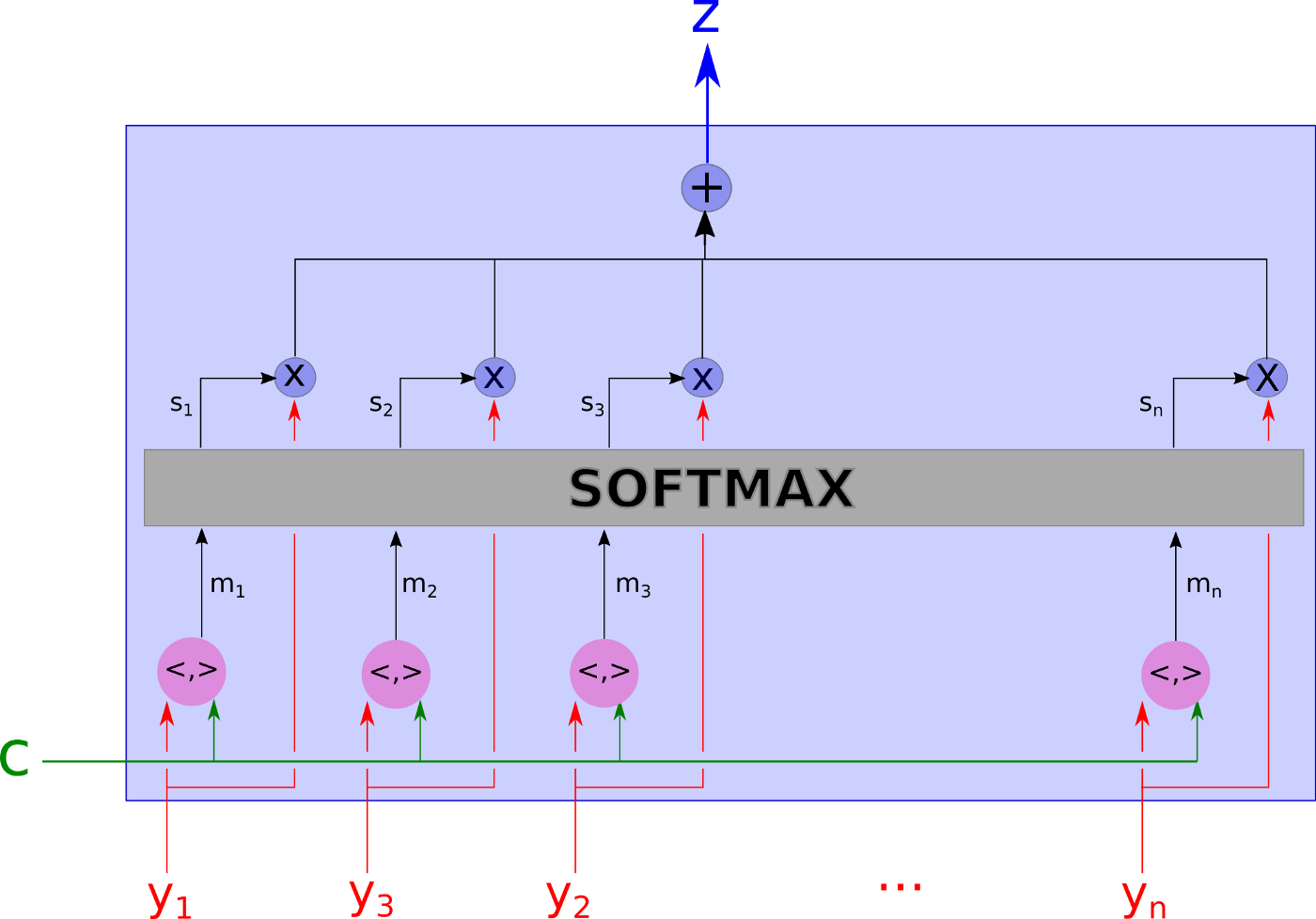
Attention model with dot-products used to define relevance of inputs vs context.
Both the last 2 figures above implement “soft” attention. Hard attention is implemented by randomly picking one of the inputs y_i with probability s_i. This is a rougher choice than the averaging of soft attention. Soft attention use is preferred because it can be trained with back-propagation.
Attention and memory systems are also described here with nice visualizations.
Attention can come at a cost, as they mention in this article, but in reality this cost can be minimized by hierarchical attention modules, such as the ones implemented here.
Now see how attention can implement an entire RNN for translation:
It can do so by stacking multiple layer of attention modules, and with an architecture such as this one:

Sequence to sequence system: an encoder takes in an input sequence x, and produces an embedding z. A decoder produces an output sequence y, by taking as input the embedding z and the previous output y of t-1.
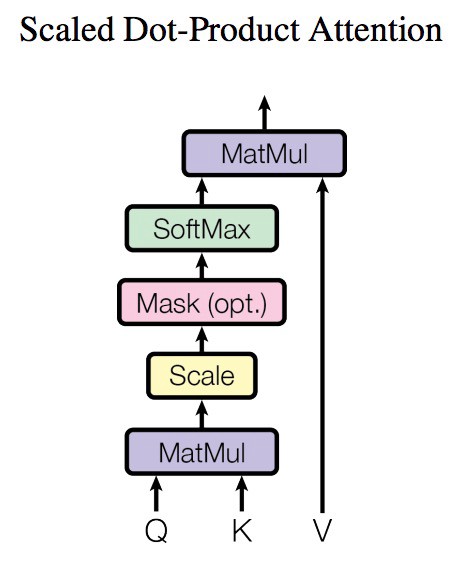
Module used for attention here. Q = query, K = key, V = values. Q and K are multiplied together and scaled to compute a “similarity metric”. This metric produces a weight that modulates the values V.
Multiple attention modules can be used in parallel in a multi-head attention:
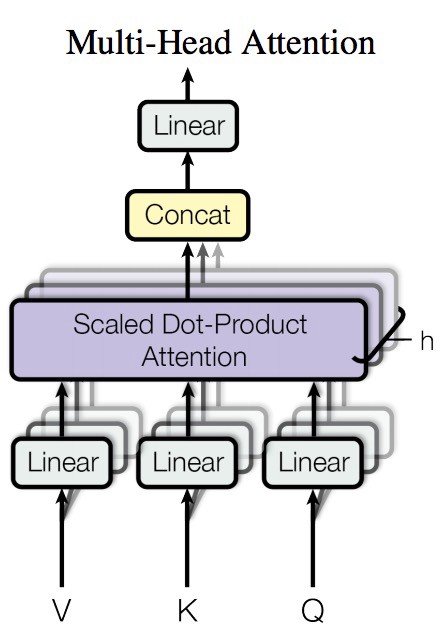
Multiple attention heads are used in parallel to focus on different parts of a sequence in parallel. Here V,q,K are projected with neural network layers to another space, so they can be scaled and mixed.
The entire attention-based network is called “Transformer” network:
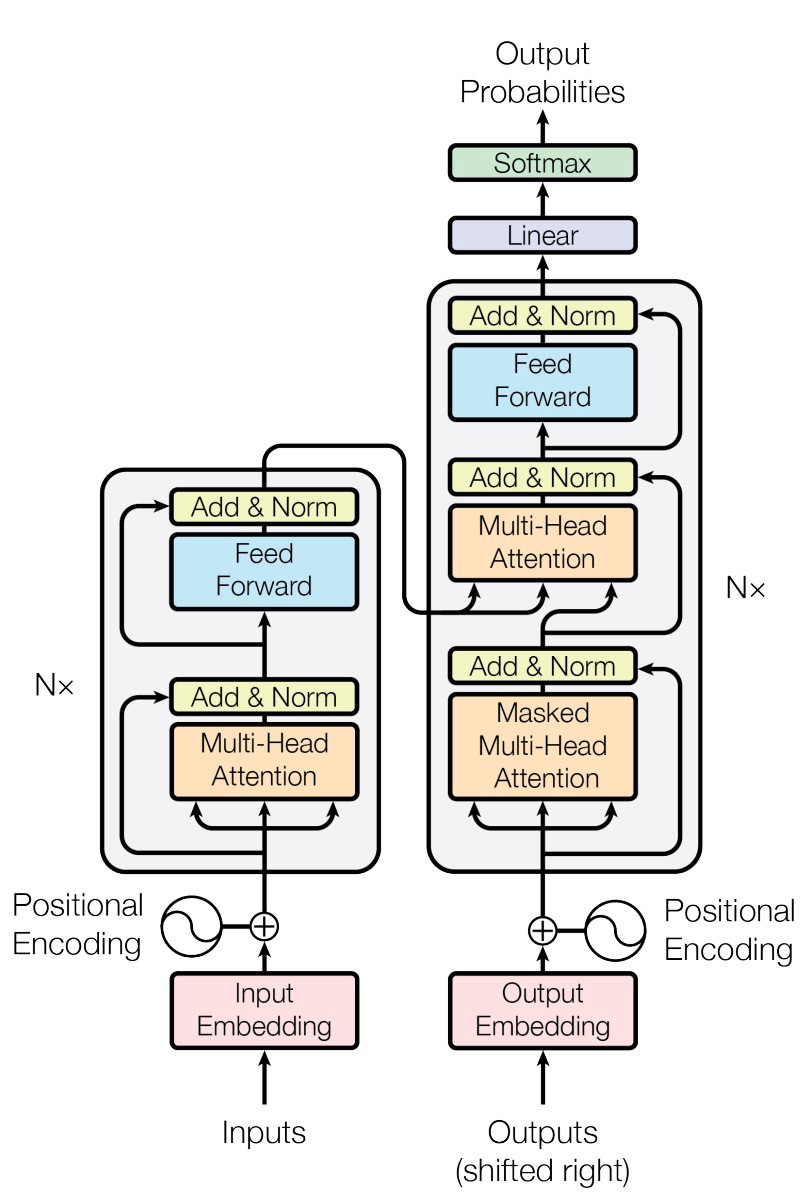
In RNN, time is encoded in the sequence, as inputs and outputs flow one at a time. In a feed-forward neural network, time needs to be represented to preserve the positional encoding. In these attention-driven networks, time is encoded as an added extra input, a sine wave. It is basically a signal that is added to inputs and outputs to represent the passing of time. Notice here the biological parallel with brain waves and neural oscillations.
But why do we want to use attention-based neural network instead of the RNN/LSTM we have been using so far? Because they use a lot less computation!
If you read the paper to Table 2, you will see these network can save 2–3 orders of magnitude of operations! That is some serious saving!
I believe this attention-based network will slowly supplant RNN in many application of neural networks.
Here you can find a great explanation of the Transformer architecture and data flow!
Memory
One important piece of work that is also interesting is Fast Weights. This work implements a neural associative memory — this is a kind of short-term memory that sits in between neural weight (long-term) and recurrent weights (very-fast weights based on input activities). Fast Weights implements a kind of memory that is similar to the neural attention mechanism seen above, where we compare current inputs to a set of stored previous inputs. This is basically what happens in the ‘Attention model with dot-products’ digram seen above.
In Fast Weights the input x(t) is the context used to compare to previously stored values h in the figure below.
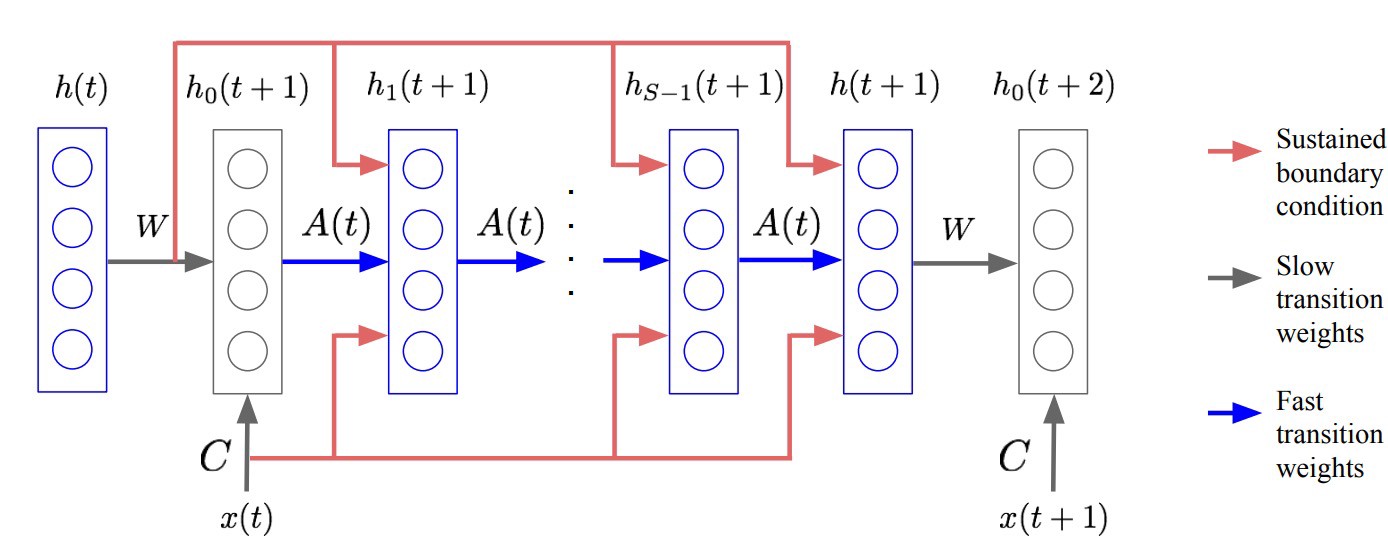
Fast associative memory implemented in Fast Weights
If you read the paper you can see that this kind of neural network associative memory can outperform RNN and LSTM networks again, in the same way that attention can.
I thinks this is again mounting evidence that many of the task currently performed by RNN today, could be replaced by less computationally expensive (not to mention using less memory bandwidth and parameters) algorithms like this one.
Please also look at: Attentive recurrent comparators, which also combine attention and recurrent layers to understand the details of a learning unit.
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…
Donations

If you found this article useful, please consider a donation to support more tutorials and blogs. Any contribution can make a difference!