Learning and performing in the real world
AKA Reinforcement Learning

In order to interact with a complex environment, living entities need to produce a “correct” sequence of actions to achieve delayed future rewards. These living entities, or actors, can sense the environment and produce actions in response of a sequence of states of both the environment and agent previous history. See figure:
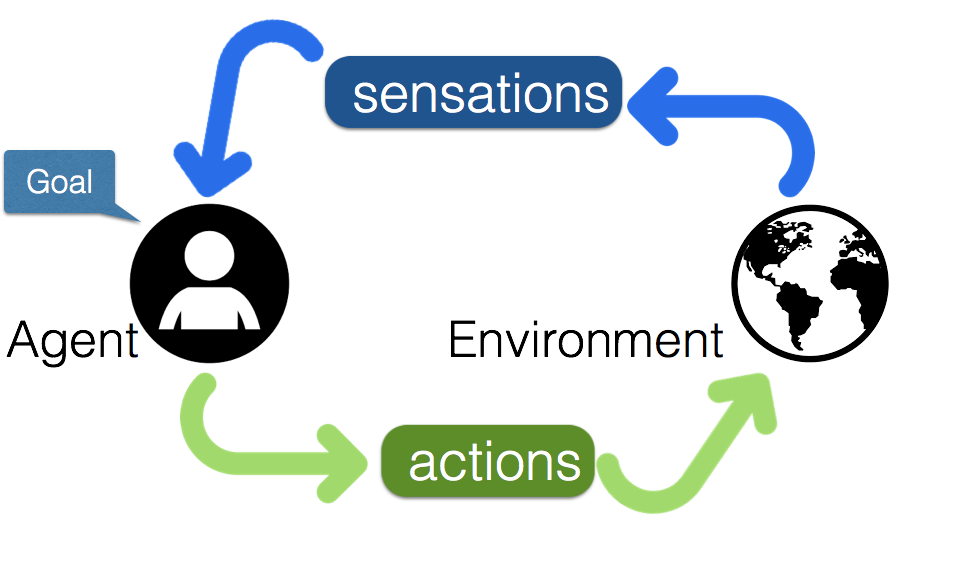
The reinforcement learning loop: an agent performs actions in an environment, and gets rewards. Learning has to occur through sparse rewards
The scenario where we want to learn to perform some tasks, is:
- actor in an environment
- actors has goals [s]he/it want to achieve
- loop: actor senses itself and environment
- loop: actor actions affect itself and environment
- delayed rewards or punishment — did we achieve goals?
- learn: how to maximize reward and minimize punishments
The actions propel the actor closer to multiple goals, where achieving even one goal may take an undefined number of steps. The agent need to learn the correct sequence of model states and actions that lead to a delayed reward by interacting with the world and performing online learning.
Recent work in artificial intelligence (AI) uses reinforcement learning algorithms to model the behavior of agents using sparse and sporadic rewards. Recent advances in this field allowed to train agents to perform in complex artificial environment and even surpass human abilities in the same contexts [Mnih2013, -2016]. Some exciting recent results in the field are learning language while performing RL tasks — see here.
Formalism
To learn to perform in the real world, given a sequence of states s we want to obtain a sequence of actions a that maximize a reward, or probability of winning.
Fundamental needs (suppose we do not know rules of games, just a list of possible actions we can perform):
- need to be able to evaluate a state — are we winning, losing, how close to a reward?
- need to be able to predict outcome from a state, action {s,a} pair — given we decided to take action a, what reward or outcome do we expect? Play mental game
- need to remember a list of {s, a} pairs that can extend over very long periods of time
There are major differences in board games like chess, go etc, where the entire game is fully observable, and real-world scenarios, like self-driving robot-cars, where only part of the environment is visible.
Fully-observable
The AlphaZero paper show an elegant approach to fully-observable games.
Ingredients of AlphaZero:
One (AZ1): a function f (neural network) based on parameters theta outputs probability of action a and value of action v (a prediction of the value of making a move).
a, v = f(theta, s)
Two (AZ2): a predictive model that can evaluate the outcome of different moves and self-play (play scenarios in your head). A Monte Carlo Tree Search in AlphaZero. These games outcomes, move probabilities a and value v are then used to update the function f.
These two ingredients make for a very simple and elegant way to learn to play these table games, and also learn without human support in a relatively short time.
Partially observable
But what about non-fully observable games? Like a 1st person shooter (Doom)? Or an autonomous car learning to drive?
A- Only a portion of the environment is visible, and thus predicting the outcome of actions and next states is a much harder problem.
B- There are too many possible options to search. The search tree is too vast. We can use AZ2, but we need to be smart and fast about which options we evaluate, as there are too many and we only have limited time to decide our next action!
C- There may not be another player to compete with. The agent here has to compete with himself, or with his own predictions, getting intermediate rewards from its ability to foresee events or not.
How do we do this?
Proposal
Unfortunately, and despite efforts in the recent years, RL algorithms only work in small artificial scenarios, and do not extend to more complex or real-life environment. The reason is that currently the bulk of the parameters of these systems are trained with time-consuming reinforcement- learning based on excessively sparse reward. In real-world scenarios, the model becomes very large (with many parameters) and almost impossible to train in short time-frames.
What we need is to be able to train a model brain to be familiar with the environment, and be able to predict actions and events combinations. With this pre-trained model brain, reinforcement learning classifier for achieving specific goals, and with a small set of trainable parameters, are much easier to train using sparse rewards. We need a pre-trained neural network that can process at least visual inputs. It needs to be trained on video sequences, and needs to be able to provide prediction of future representation of the inputs.
In order to surpass these limitations, we are studying a synthetic model brain with the following characteristics:
- active in an environment, can sense and act
- memory of sensory sequences, actions and rewards
- attention: only focus on data that matters (see this)
- predictions: predict actor and environment future states, so we can perform online learning — by predicting we can understand what we know or do not know and have a “surprise” signal for when we need to learn (see this and this). Predictions also do not require supervisory signals, as they can be tested for errors agains actual future events and their outcomes.
The key is to be able to predict outcomes — function f (AZ1) needs to have predictive capabilities, in other words it needs to have the ability to foresee the future.
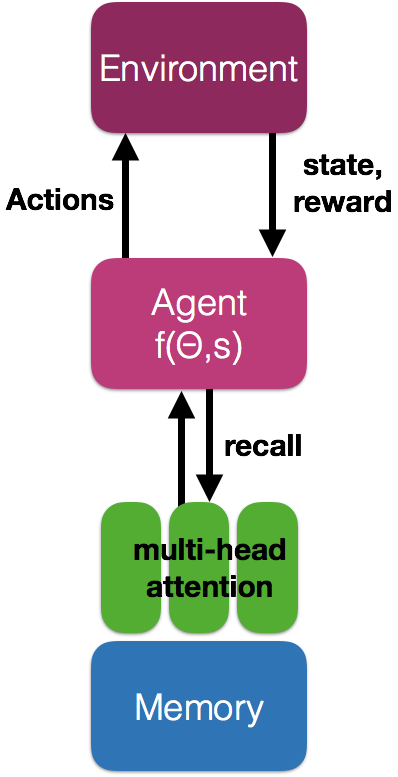
A proposal for a neural network that can understand the world and act in it. This network uses video and can predict future representation based on a combination of the state s and its own associative memory. A multi-head attention can recall memories and combine them with state s to predict the best action to take.
On the left, you can see a proposal for a neural network that can understand the world and act in it. This network uses video and can predict future representation based on a combination of the state s and its own associative memory. A multi-head attention can recall memories and combine them with state s to predict the best action to take.
This model is able to perform well in multiple conditions:
- continuous learning: we need this model to be able to learn multiple task at once, and learning without forgetting, so older task are not forgotten
- one-shot learning and transfer learning: we need this model to be able to learn from examples, both real and synthetic
- virtual replay: the model is predictive, and can predict different outcomes even after the events have been witnessed. It can play and replay possible action in its mind and chose the best one. The associative memory is acting as a search tree.
How do we train this synthetic brain?
- mostly unsupervised, or self-supervised
- little supervision here and there, but no guarantee of when
But designing and training a predictive neural network are current challenges in artificial intelligence.
We argued in the past for a new kind of neural networks, which have showed to be more effective in learning RL tasks.
We also like the predictive capabilities of Capsules, which does not require a ground-truth representation, but is able to predict next layer outputs based on the previous layer.
Note 1: this is a great post on why RL does or does not work well and the issues associated with it. I agree a lot of RL these days is highly inefficient and there is no transfer-learning success story. This is why we should push approaches to pre-train networks, curriculum learning and breaking the task into many simpler tasks each with simple rewards. One solution to all problems is hard if your search space is so large!
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…