Deep Neural Network Capsules
A recent paper on Capsules has many important insights for revolutionizing learning in Deep Neural Networks. Let us see why!
Interesting characteristics of capsules
Here is a list of important points in the paper and video lecture:
- coincidences in high-dimensional spaces are [very] rare, and when they occur, it is because the data “agrees”. Objects are composed by parts with specific arrangements, when multiple objects parts, say: two eyes lay above a mouth, the probability a face (a higher-level object) presence is high. But if object parts are not in the correct position, it means a higher-level object is not present. One eye with a mouth on side and another eye above is not a face!
- the power of deep neural network is in how we connect layers together. We use fully-connected matrices to connect all features in one layer to all features in another layer, but this, beside for computational efficiencies, makes no sense! If the “eye” and “mouth” neurons in a layer l connect to a “face” neuron in layer l+1, that makes sense. But if we connect “eyes”, “wheels”, “hands”, etc to the neuron “face”, this will lead to more confusion of information, and poorer performance. For this reason we seek an algorithm that can guide the connection between layers in a more meaningful way than purely fully-connected layers, hoping that optimization algorithms will find the way… And if we have a better connection scheme, these optimization algorithms will more frequently find better and faster solutions
- deep neural nets learn by back-propagation of errors over the entire network. In contrast real brains supposedly wire neurons by Hebbian principles: “units that fire together, wire together”. Capsules mimic Hebbian learning in the way that: “A lower-level capsule prefers to send its output to higher level capsules whose activity vectors have a big scalar product with the prediction coming from the lower-level capsule”
- in standard deep neural networks like AlexNet and ResNet, pooling between layers that downsample is a MAX operation over a fixed neighborhood (receptive field) of pixels (eg.: 2x2). This maxpooling layers have no learnable parameters. A better idea is to let layer learn how to pool and from a larger receptive field. An even better way is to do so in a dynamic way, just like in the Capsule paper. “For each possible parent, the capsule computes a “prediction vector” by multiplying its own output by a weight matrix” and as such capsules are connected via a “powerful dynamic routing mechanism to ensure that the output of the capsule gets sent to an appropriate parent in the layer above”. In summary, “This type of “routing-by-agreement” should be far more effective than the very primitive form of routing implemented by max-pooling”
- output is a vector, which allows for dynamic routing by agreement (last point above)
- compared to standard CNN such as AlexNet etc, capsules “replac[e] the scalar-output feature detectors of CNNs with vector-output capsules and max-pooling with routing-by-agreement”
- prediction: this is an important point that may go unobserved! Capsules predict the activity of higher-layer capsules. Predictive neural network capabilities is something we have been advocating for years, see: here and here — a new kind of neural network: predictive networks! We believe this is a EXTREMELY important characteristic of Capsules that can set up apart from standard neural networks, as we argue in the linked posts
- Capsules are like cortical columns in human brains
- Capsules are supposed to produce equivariant features, like a 3D graphic model: given the model with just a simple transformation we can derive all its poses
- Capsules combination of capsules encodes objects parts AND their relative positions, so an object instance can be accurately derived from the presence of the parts at the right locations, and not just their presence
Network details
Here is a picture of CapsNet, the neural network architecture using Capsules. The interesting dynamic routing occurs between PrimaryCaps and DigitCaps.
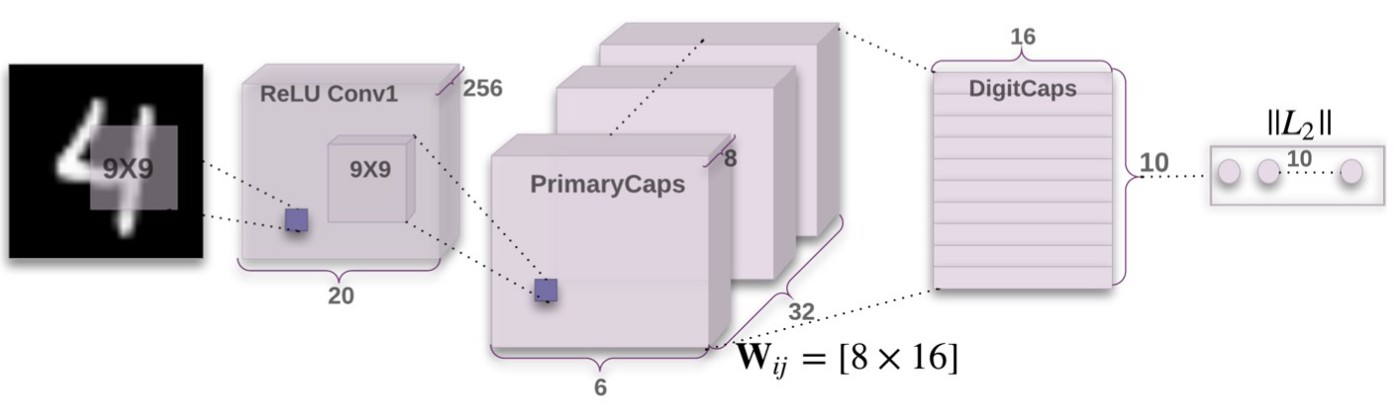
CapsNet, the neural network using capsules. The interesting dynamic routing occurs between PrimaryCaps and DigitCaps.
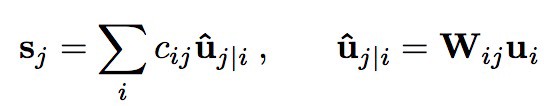
Dynamic routing is implemented with two main transformation as reported in these equations (2 in paper). U are the outputs of Capsules in the layer below, and S are outputs from Capsules on layer above. U_hat is a prediction of what the output from a Capsule j above would be given the input from the Capsule _i_in layer below. This is very interesting as an instantiation of predictive neural networks.
| W_ij is a matrix of weights (like a linear layer) going from all capsules from one layer to the next. Notice there are as many W matrices as i*j. c_ij is another matrix that combines the contribution of lower layer capsules into the next layer output. Coefficients c_ij are computed with the dynamic routing algorithms described in the paper. The important point is that this is done by computing the agreement between the real output of next layer v and the prediction _h_hat: b_ij ← b_ij + uˆ_j | i * v_j_ |
Notes
Note 1: We like this paper because Capsules agrees with a lot of the work and thoughts we had in previous years, and that we named “Clustering Learning”. See our previous publications here:
https://lnkd.in/dnSgjJU
https://lnkd.in/dmNbuVs
Note 2: Capsules video by G. Hinton
Note 3: great blog post on this part I and part II.
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…