Notes on Transformer neural network for sequence to sequence learning
This post are notes to understand sequence-to-sequence (s2s) neural networks and in particular the Transformer neural network architecture and training. It extends concepts introduced in this post.
Intro: neural translation with attention
First we should go back to the origin of neural translation. See figure below. A sentence in language A is first “read” by an encoder (blue). The sentence is then translated to a language B by a decoder network (red).
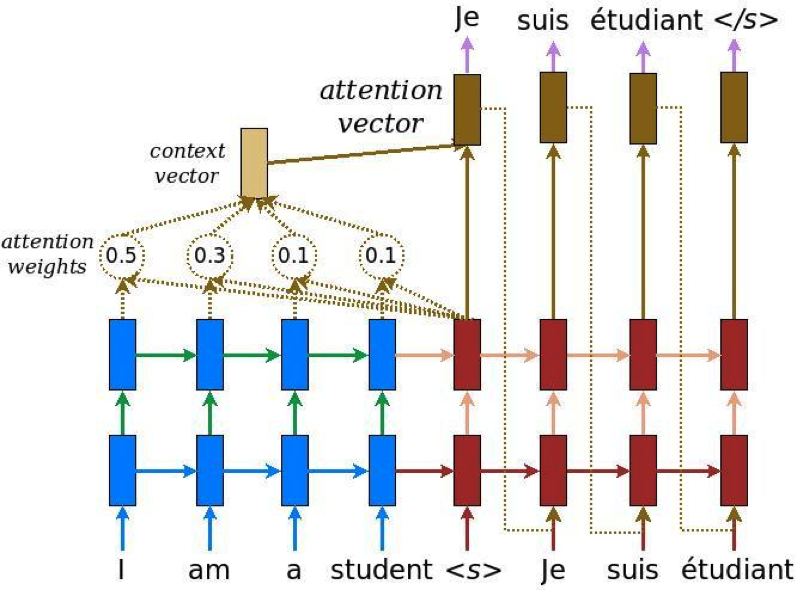
LSTM neural translation network with attention
The figure above actually represents a sequence of steps that are performed one after another to produce a translation. The figure tries to represents the entire process, but this may confuse the readers as the process has multiple sequential steps. Let us see those steps in detail:
1- read the input language sentence A, encode word by word and sequentially feed them to the encoder LSTM
2- after the end of sentence A, the decoder LSTM will start to produce the translated sentence B, one word at a time, and starting with a begin-sentence token .
3- for each output of the decoder (corresponding to an input word of sentence B), use the outputs of the encoder as “context” to an attention module — this means that the the decoder output is gated by attention based on the relationship between the language B word and all the words of the sentence in language A. Notice that the decoder is auto-regressive: it uses its previous output words of language B to generate the next word.
4- repeat 3 for all sentence B words, and the decoder will produce all translated words
Transformer
Similarly for the Transformer, the digram from the original paper can be confusing. There are a lot of thing happening in this figure and they are all sequential! And actually the steps are very similar to the LSTM-based neural translation with attention explained in the previous section.
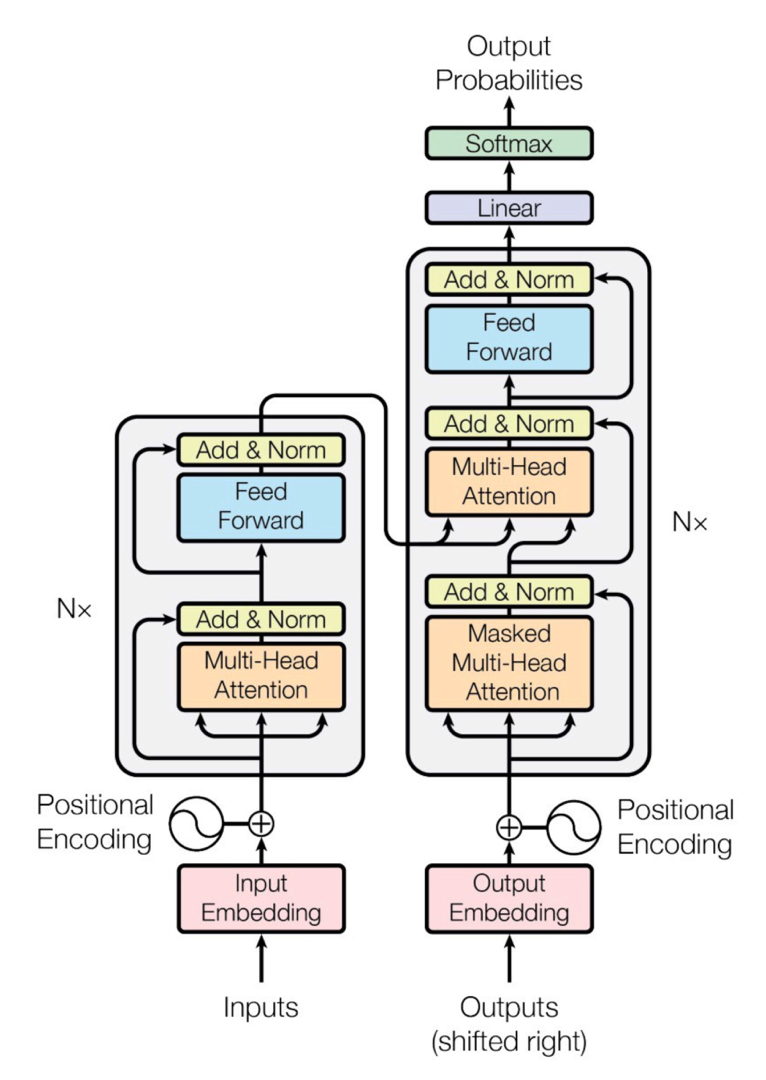
The Transformer also have and encoder (left block) and a decoder (right block). The input sentence from language A is also fed and processed by the encoder before a translation is produced by the decoder. But here we do not have an LSTM, so there is no concept of “time” or sequence steps as there is in RNN/LSTM networks. For this a positional encoder is added to literally add the concept of “passing time” or sequential positions in the sequence. This is also done in the decoder.
The sequence of processing steps is best described in the original blog with the animation given below:
1- the sequence A is encoded. Self-attention is applied at each encoder “layer” so that each new word input is fed to an attention module with all the other words in the sequence A as a “context”. This allows to learn relationships between words in language A that help to translate to language B.
2- the decoder works similarly to the example in the previous section, using the encoder to serve as “context” to the translated words. This feeds from the connection that go from encoder to decoder in the Transformer figure above.

Sequence of steps in the Transformer
Credits: Much to thank these guys!
References:
The Transformer - Attention is all you need.
Transformer - more than meets the eye! Are we there yet? Well… not really, but… How about eliminating recurrence…
mchromiak.github.io
Transformer: A Novel Neural Network Architecture for Language Understanding
Neural networks, in particular recurrent neural networks (RNNs), are now at the core of the leading approaches to…
ai.googleblog.com
The Annotated Transformer
The Annotated Transformer
The Annotated Transformernlp.seas.harvard.edu
OpenNMT/OpenNMT-py
OpenNMT-py - Open Source Neural Machine Translation in PyTorch
github.com