Learning neural network architectures
how to automatically create neural networks
Last time we talked about the limits of learning and how eliminating the need for design of neural network architecture will lead to better results and use of deep neural networks.
Here we will analyze all recent approaches to learning neural network architectures and reveal pros and cons. This post will evolve over time, so be sure to log in from time to time to get the updates.
First of all…
What does is mean to learn a neural network architecture? It means to try to combine all neural networks building blocks in the best way to obtain the highest performance in some task, say: categorizing ImageNet images.
Here you can see all recent neural network architectures of the past 10 years or so. All of these architecture have been crafted by humans by intuition and raw brain-power. This is human intellect at his best, but as you can imagine, it may not always lead to the best solutions. As we mentioned here, this is not the way to progress, as we will be limited by what human minds can come up with and never fully search the large space of neural architectures. Think about what happened with the games of chess and go recently! Humans were beaten to a pulp by neural network algorithms searching the space for the best moves and strategies.
neural network algorithms will beat human in the area of neural architecture search, in the same way they beat them in go and chess!
So the way to go is really to use neural networks to search for better and better neural architectures. Effectively we will use the same gradient descent techniques to guide the immense search of neural architecture.
But as you can see there are many possible neural building blocks and the search space is immense. Imagine we have try all possible convolutional layers: different number of inputs outputs planes, dilation, depth-wise, pooling, non-linearities, etc… the search space can be from 10¹⁴ to 10²⁸or more options! This is an immense space. Imagine it takes us 1 hour to train and test one architecture… well we will need 10¹⁴ hours, or an eternity!
Gradient-based methods
Controller based methods such as Zoph, Le (2017) uses a recurrent neural network to create new architectures and then test them with reinforcement learning.

An overview of Neural Architecture Search
They encode the connectivity and structure of a neural network into a variable-length string, and use the RNN controller to generate new architectures. The “child network” is the trained on the dataset to produce train and validation accuracies. The validation accuracy is used as a reward signal to train the controller. This in turns produces better neural networks in the next iterations, as the controller improves in the search over time.
Liu at al. (2017) uses heuristic search to start from simple neural network structures and progressively add complexity. This paper builds on the work of Zoph et all (2018). In the latter paper, they use again the same RNN controller to search for architectures:

Controller model architecture for recursively constructing one block of a convolutional cell.
This controller produces a sequence of outputs that encode each of the element in the top of the figure above, basically: which previous two layers to use, which operation to apply to each of 2 inputs, and which method to combine their 2 outputs into a single output.
In order to reduce the number of possible combination of parameters, they use a fixed constructed block architecture illustrated in the figure below. This block can implement residual-like layers and googlenet-type layers. They allow the RNN controller to find multiple blocks fora each layer, generally 5, a good compromise between effectiveness and search space.
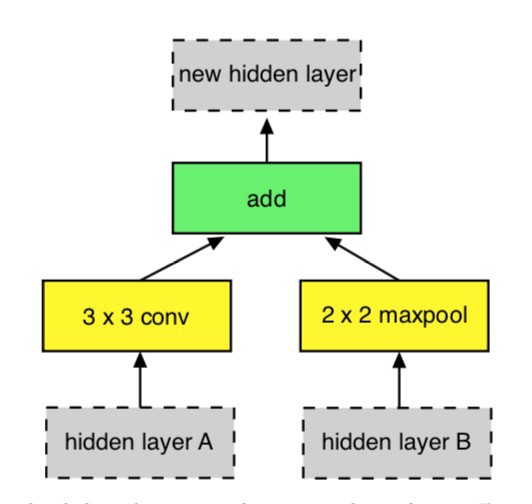
Example constructed block
In this work, they also limit the number of possible basic building blocks to the following list:
- identity; 1x7 then 7x1 convolution; 1x3 then 3x1 convolution; 3x3 average pooling; 3x3 or 5x5 or 7x7 max pooling; 1x1 or 3x3 convolution; 3x3 or 5x5 or 7x7 depth-wise separable convolution; 3x3 dilated convolution
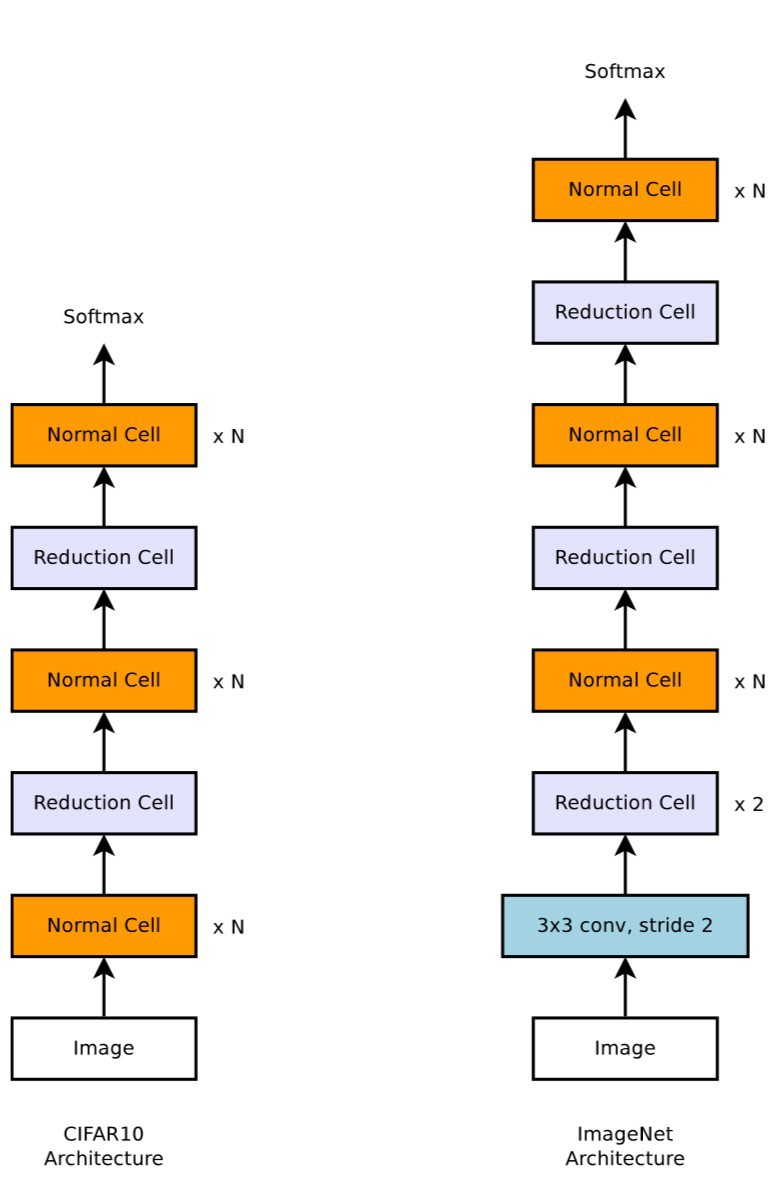
Scalable architectures for image classification consist of two repeated motifs termed Normal Cell and Reduction Cell.
They create architectures such as the ones on the left side image. Based on previous architecture history, they decide that the overall architecture should be composed of two types of cells: (1) convolutional cells that return a feature map of the same dimension or Normal Cell, and (2) convolutional cells that return a feature map downsampled by two in height, width or _Reduction Cel_l. Notice that in these architecture they also double the number of filters in the output whenever the spatial activation size is reduced in order to maintain roughly constant hidden state dimension. Notice also that this architecture on the left picture is somehow similar to the blocks in ResNet, including the choice of normal and reduction cells.
In order to train the Controller RNN, they use reinforcement learning. Once an architecture is produce by the RNN, it is trained. Using the accuracy in the validation datasets, a reward signal is generated and used to provide feedback to the RNN controller, eventually training it to be better and better at architectural search. Since the reward signal is non-differentiable, they use a policy gradient method such as REINFORCE and by using a moving average of previous validation rewards subtracted to the current validation value. Effectively this acts as a delta-improvement metric on validation accuracy.
Interestingly below you can see the best cells found by the algorithm in the figure below. They seem to be more complex version of the Inception-ResNet layers.
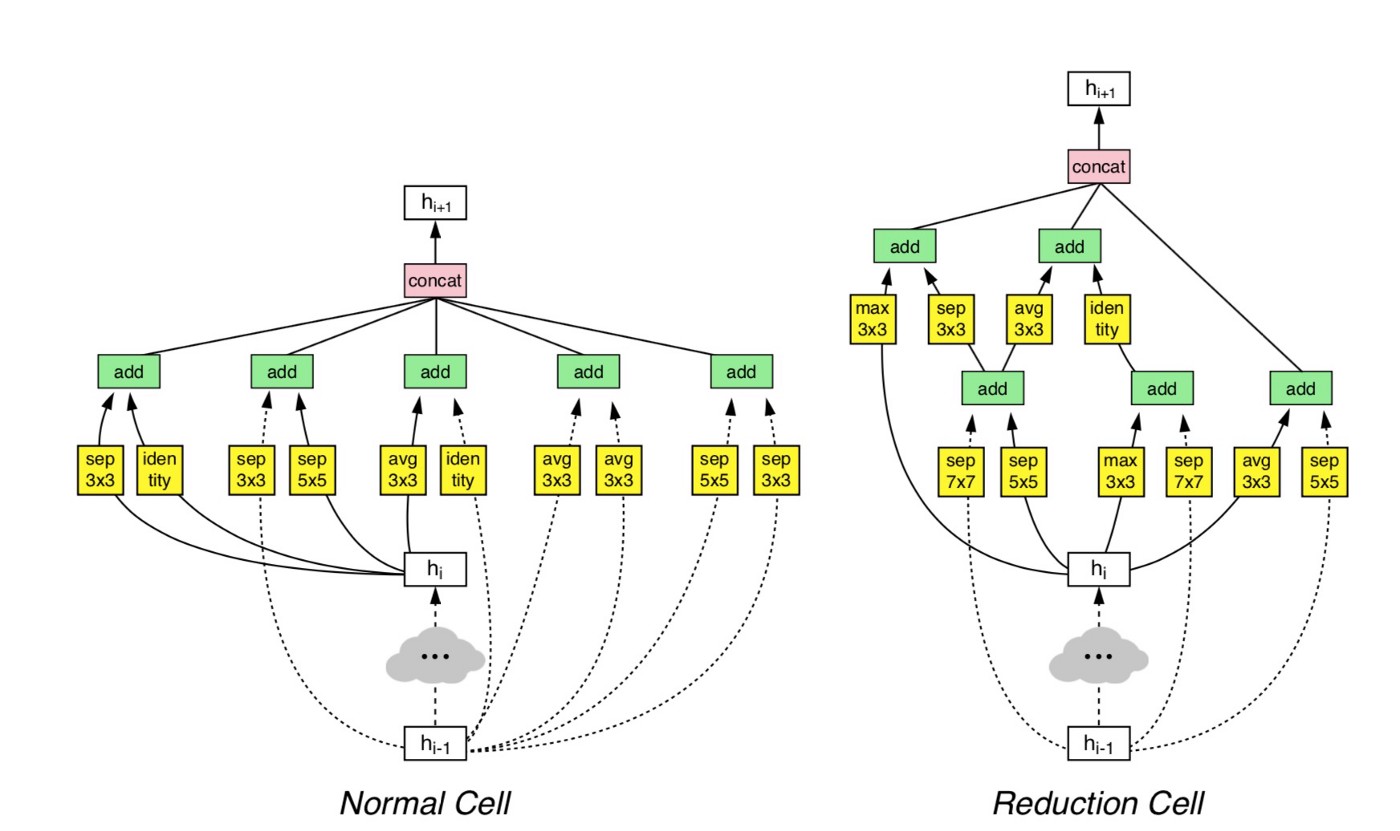
Architecture of the best convolutional cells (NASNet-A) with B = 5 blocks identified with CIFAR-10
The results are nice! They find both large and small neural networks that are very efficient and high-performance compared to human hand-crafting. Below we report a table of the small models.
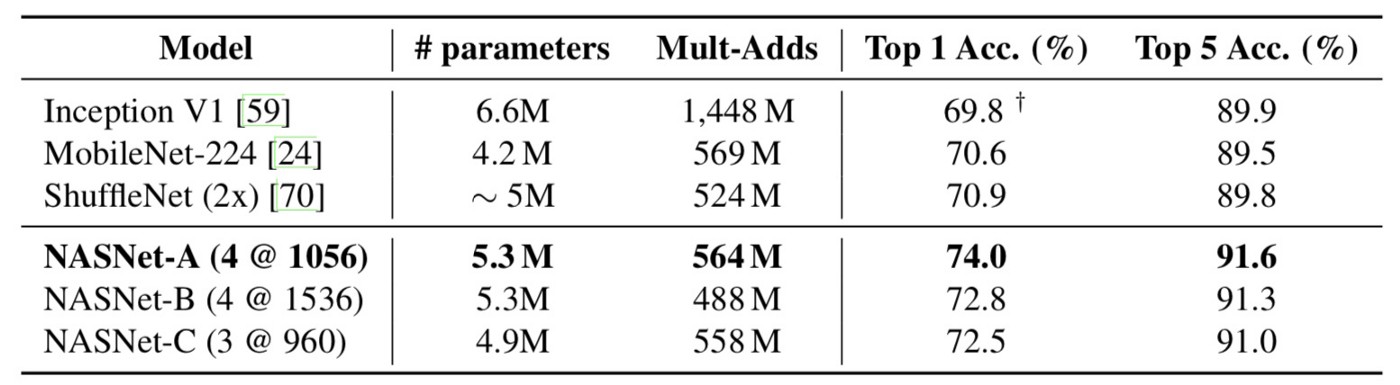
Performance on ImageNet classification on a subset of models operating in a constrained computational setting, i.e., < 1.5 B multiply-accumulate operations per image
Finally the paper make some useful remarks regarding the performance of reinforcement-learning search versus random search. In past efforts beating random search was surprisingly hard. RL search is better an finds a lot better models, but it is also surprising how much random search works well. After all that is what created our human brain, but only took some hundreds of thousand of years and 5 billion before that…
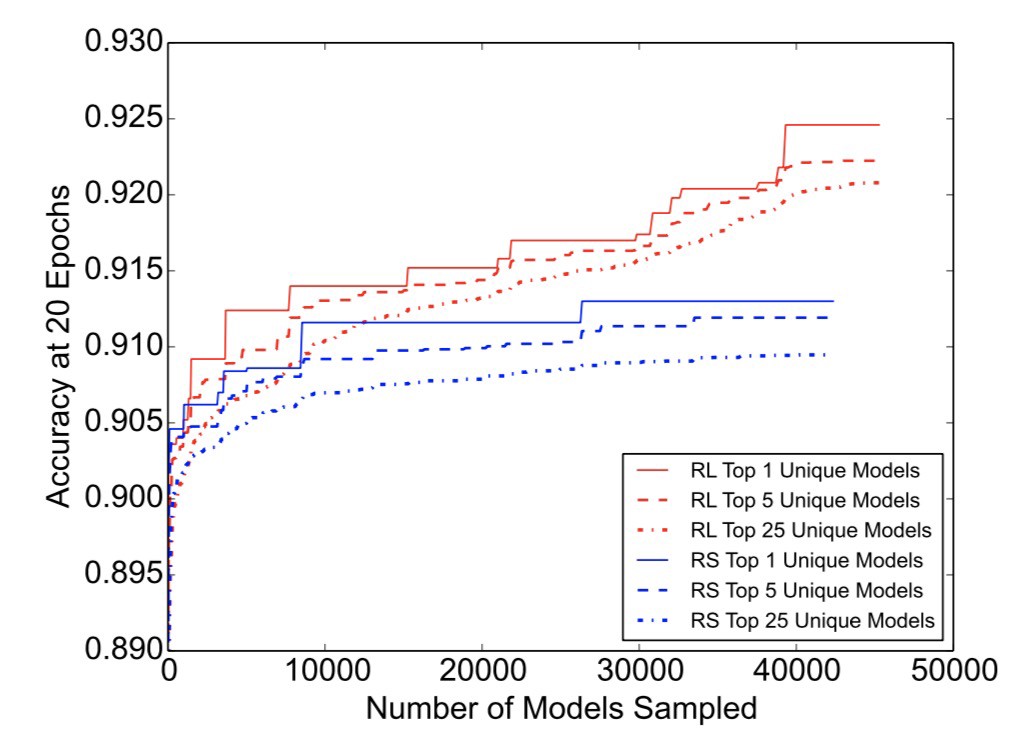
Comparing the efficiency of random search (RS) to re- inforcement learning (RL) for learning neural architectures
In overall this is quite a guided search for models, but the methodology and results can be used for many different kind of neural networks. We expect to see this technique used a lot more in the next few years. One drawback is that the model architecture used is very much similar to ResNet block architecture. Also the constructed block only captures a subset of possible sets. This is of course all done to reduce the search space and make the problem more tractable, but it does not for example generalize to encoder-decoder architectures or more niche applications. For those, one would have to create new constructed blocks and base networks.
In addition the search for architecture is very computationally intensive, and take a lot of time. You need 500 GPUs (expensive one as NVIDIA P100!) and you need to test 20,000 neural networks over 4 days to find results.
Genetic search
Genetic search are exhaustive search methods that create different neural architectures and then try them one by one. As such they are often limited by the slow process of unguided search. Examples are Wierstra et al. (2005), Floreano et al. (2008), Stanley et al. (2009). These methods use evolutionary algorithms to search new architectures.
Neuroevolution is a recent approach that found success in reinforcement-learning algorithms. It had recent success in reinforcement learning tasks where other algorithms (DQN, A2C, etc.) failed.
Pruning as network architecture search
Recently pruning of neural network has been revisited as a technique for neural network architecture search. This paper shows two major insights: 1) one can start with a pruned neural network and train it from scratch; 2) pruning can thus be seen as a technique to optimize neural network architectures similarly to network architecture search.
Notice that pruning does not produce as good results as the gradient-based search techniques discussed above.
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…