At the limits of learning
Deep learning success lies with the promises of neural networks being able to learn from data. This is in contrast with the way we designed and tested algorithms before the year 2000. Before neural networks and deep learning became popular, human intellect and its crafting abilities were at the heart of invention of algorithms. Humans would think and think and think on how to solve a task, often breaking it down into smaller portions that humans deemed “easier” to tackle. Humans designed the algorithms with intuition and raw brain-power, testing the algorithms and adapting the necessary parameters in a second step.
The promise of neural networks, like the one below, was that most of the algorithm could be learned directly from data, if only we provided examples of input and desired outputs.
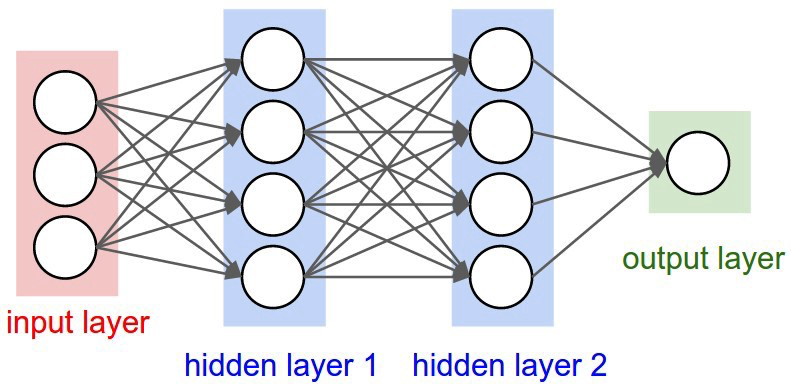
neural networks
And neural networks are simply trained with the back-propagation algorithm, where the most important details are: the input data, the desired output data or label, a way to estimate error via an “error function”, and a way to update weight based on this error.
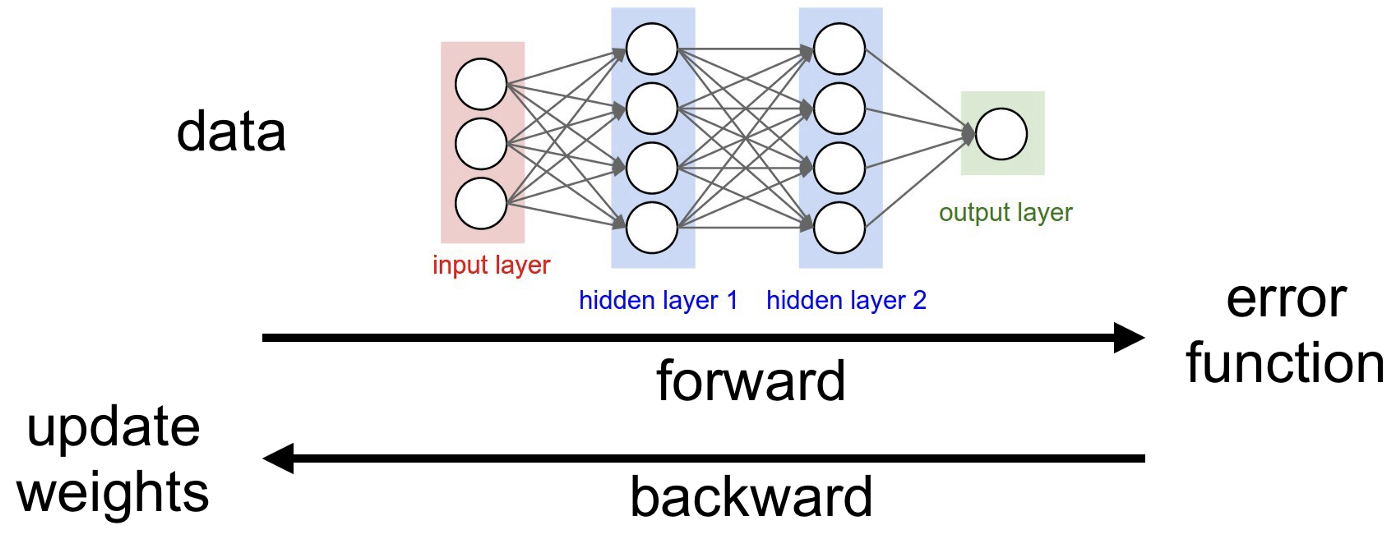
training of neural networks
With neural network there was this implicit idea of
man vs machine
where man is not at the hearth of designing algorithms any longer, now it is a machine, or rather another algorithm, that could do that much better than a human can. Because neural network can approximate any function, even complex functions as the one need to find your eyes in a picture of your face. And that require a lot of parameters, hundred of millions even! No human brain could tweak so many parameters in their mind.

who concocts the best algorithms?
The purpose of this blog post is to show that the promise of neural networks are only partially fulfilled, and that after all it is not an algorithm that decides — maybe we are:
At the limit of learning
3 issues:
If you look at the way we train a neural network today, humans chose the datathe network uses to learn. Humans chose the task set for the neural network. And of course! We need it to perform a task we need solved! But by having a neural network solve only one task, or small subset, we limit it generalization and ultimately its performance. More on this later.
But one thing that has been bothering us almost since we started using neural networks, is that humans chose the architecture of the neural network. Meaning they chose how many layers, how many neurons per layer, how layers are connected. And to complicate the matter further the architectural design space is immense. Because neural networks are not as simple as the example below. They can use convolutional layers, each with many parameters, they can pool neural maps, they can bypass, they can use gating, and so forth. See here and here for more details.
In addition, humans decide what the error function should be. And this has the ability to force the network to learn specific details and use defined metrics to learn the task at hand. Given a dataset (data), the neural network is significantly different depending on the error we are set to compute. This gives human another powerful tweaking tool on the design and implementation of neural networks!
who decides?
In summary, because of these 3 issues, we are somehow back to where we we started: humans make a lot of choices and spend an immense amount of time tweaking algorithms, data, functions, architectures to get better at some tasks, and often fail to create something more general that can tackle multiple tasks at once, not just the task at hand~!
This is an issue we may need to solve to tackle larger problem, such as reinforcement learning.
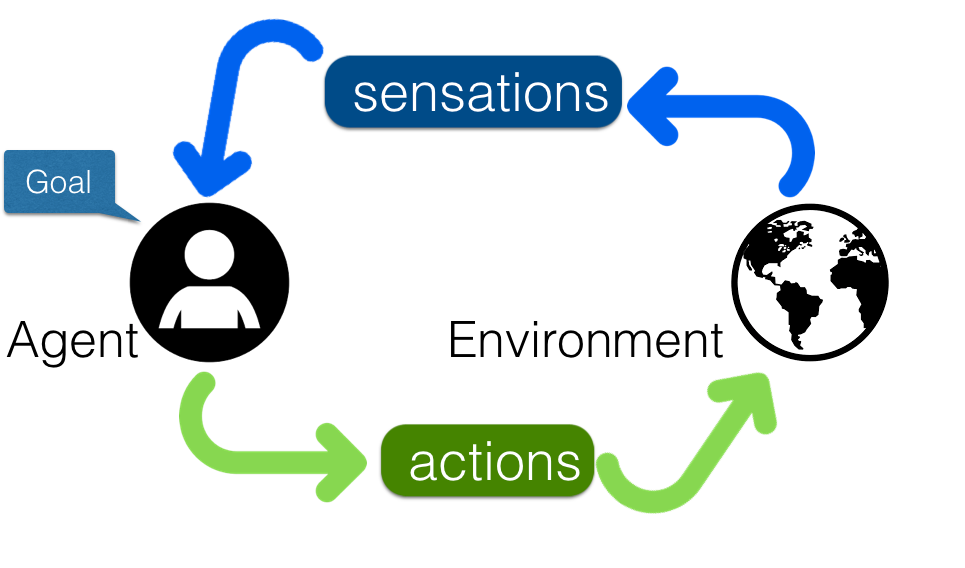
learn by doing
In reinforcement learning (RL), a neural network or agent is not designed to solve just one task, such as categorizing cats and dogs — rather it is supposed to work out a complex model of the environment via sensing and learn how its actions affect the environment and its future decisions.
If only we had a brain
If we had a brain, or a rather large neural network that was pre-trained to “know about the world” we may have a great starting point for an agent learning to navigate in an environment. This “brain” would contain million of parameters and maybe trained with a good model of the agent and the environment.
And if we had a brain, we could just add a little tiny classifier that can learn to solve our problem using only rewards as learning signal. Rewards are sparse, so having a small learning module is necessary to learn fast and efficiently. See more about this here.
What to do?
The main question that we should work on now is how to create such “brain”. This involves defining a learning architecture, data and error functions that are “generic” and we may not tweak. Rather, we will focus on demonstrating what this “brain”can and cannot do using reinforcement learning tasks (playing a video game, for example)
Predict

a brain that can predict the future
We propose to focus on the task of predicting the future as a possible way to train a generic “brain”. We talked about a new kind of neural networks that can do this here. This predictive network can use unlabeled videos as a source of data, videos of the environment from the agent point of view. Learning will aim to reduce a prediction error, tested again the future frames of a video
But predict what? That is the question! In the past we worked on predicting future video frames, which they learned well. But there may be a better task than learning the value of pixels. We may want to learn how objects move, for example predicting optical-flow or object-background segmentation. This is work in progress. Can you think and suggest ideas?
These networks have also shown they they can better categorize using multiple passes over the input. And also be much less sensitive to adversarial attacks, since they are trained on video frames and thus learn the complex spatio-temporal transformation of object and the visual field during egomotion.
After training such a “brain”, we can show that reinforcement learning tasks learned a lot faster by just adding a classifier.
Much more work and ideas are needed. Are you interested in helping us?
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…