Continual learning
How to keep learning without forgetting
By Eugenio Culurciello and Vincenzo Lomonaco
Today we mostly train neural network based on fixed pre-determined datasets. This gives very good results on a large variety of tasks. On the other hand, many tasks will require the dataset to evolve with the experience of the agent or the life of the agent. Imagine a robot that needs to learn new objects or new tasks or new concepts while operating! How can we do this?
Forgetting
Suppose you have a neural network beautifully trained for your task. Let us say that we learned to identify N classes, where N is 2 in the figure below.
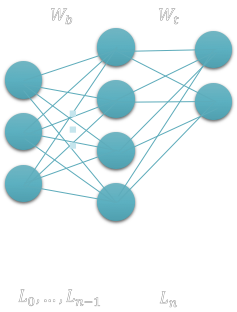
Fig. 1: Initial neural network, with Ln as final layer
Now, we would like to extend this neural network to more classes, from N to N1, say 2 more classes as we show in the image below.
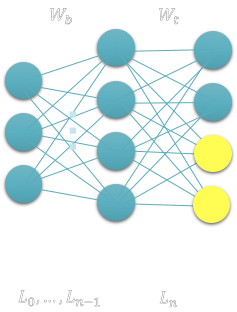
Fig. 2: We now want to add two more categories to our neural network, the yellow neurons / outputs
Turns out this is quite easy to do in practice: we take the previous dataset D that we used for the N classes, and add the new classes to it, so now we have a new dataset D1 with N1 classes. We can again train our neural network with gradient descent and get good results. Business as usual.
The problem
But there is a problem: imagine we need to use this algorithm on a robot that constantly has to learn new categories as it explores an environment. The robot may not have resources on-board to keep a copy of the training dataset D and also may not have the resources to re-train an entire model from scratch.
In the previous section, when we mentioned that we would re-train the network, we did not explicitly say that it was the full network! That requires some large resources. Recently you can train an ImageNet in 20 minutes or so, but only with large TPU or GPU hardware.
Clearly if we could train just the last layer of the network, that would be better. But we can do that! For example, we can just store the embedding of all dataset D1 at the output of layer L_(n-1), and then be able to train the last layer on the robot with limited resources.
If we want to re-train the entire model, we could send data collected by the robot to a cloud system, if we had the connectivity, bandwidth and power to do so. But that would be a better approach, so multiple robots could update a single giant model in the cloud, and maybe receive an update every now and then. If we do this, however, we have to consider the effort we pose on our system: training a large neural network from scratch is onerous and expensive, and it not always possible or economical.
The issue then becomes: how can I learn new categories with the minimal footprint? Using the least resources in terms of data and computation (proportional to energy, cost)? This is what this article is about!
But continuing to learn is not just about learning new classes or categories, sometimes it is also about multiple tasks.
Multiple tasks
Our neural network could be used for multiple tasks, say it was ready for task T1, but then want it to learn also task T2 and T3. We can learn 3 separate classifiers of part of the network to solve each task.
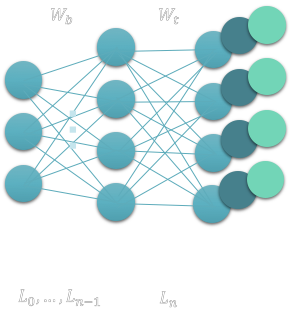
Fig. 3: Example neural network with multiple tasks: each one is a different classifier added to perform a different task
If we train on each of them, and each classifier is not sharing weight, then we will be ok. But if we have the 3 tasks share weights or part of the network, then we will witness the phenomenon of catastrophic forgetting, meaning that when learning a new tasks, old ones are forgotten! An example of catastrophic forgetting in PyTorch examples is available here.
What to do?
Vincenzo’s work and thesis has been devoted to helping to solve these issues. We will summarize them here to help our audience understand how to tackle this interesting problem of deep learning today.
There are many proposed solutions, but we will focus here on some that Vincenzo and his team have found to be superior and effective. In particular we suggest to focus on:
- Copy-weights with Re-init (CWR)
- Architect and Regularize (AR1)
Learning without Forgetting (LWF)
Imagine we are in the situation of Fig. 2. If we want to add new classes and re-train part of the network, in order to prevent forgetting, we will have to make sure that the original neurons output is kept as close as possible to the original values. This means we try not to change the original weights and neuron outputs, we only modify the new weights affecting the new neurons.
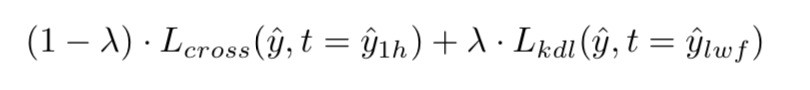
New loss: cross-entropy plus a term to limit change in outputs of previous neurons
The original paper is here.
Elastic Weights Consolidation (EWC)
Find out which weights have the most importance and try to change them as little as possible when continuing to learn new tasks or categories.
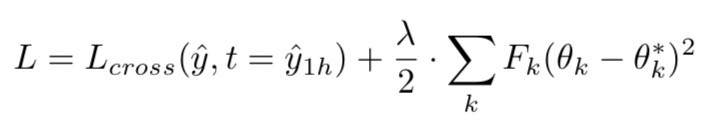
New loss: add cross entropy loss to a penalty square term for changing important weights.
F_k can be computed by summing all the derivative of the loss with respect to the weight k for a given batch.
The original paper is here. Synaptic Intelligence (SI) is a variant.
Copy-weights with Re-init (CWR)
This is a simple yet effective methodology to prevent forgetting by Vincenzo and team.
Suppose we have a neural network with some weight we keep fixed (Wb or consolidated weights):

Part of the networks is fixed (consolidated weights)
We then train for 1ask T1 exemplified by the new green added neurons, the weight Wt are temporary weights we use for training only.

We train for task T1 on the green neurons
After, we copy the weights to a consolidated weight storage called Wc
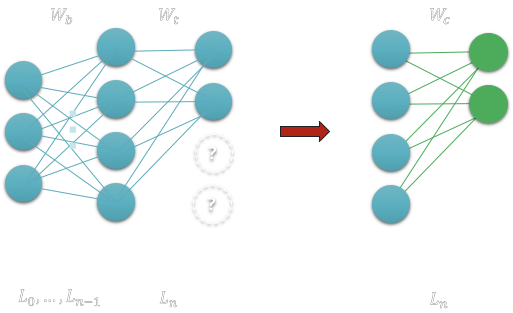
Then we proceed to learn task T2 on the new neurons and weights in green.
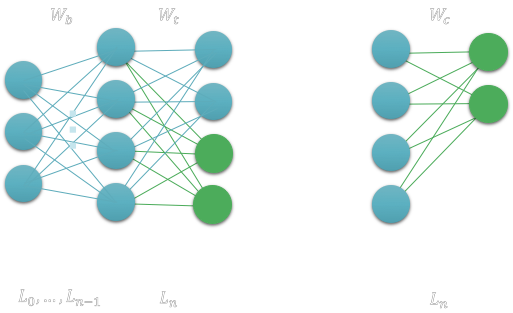
We then copy only the new green weight to the consolidated weights. This way we do not interfere with the training and weights previously learned for task T1. Note that we will have to scale the weight as we copy them to Wc, since there may be a difference in the training batch sizes. Without scaling, if we present a sample of T2, the activation of neurons learned in T1 may activate more that the ones for T2, when actually T2 activations should have been higher. In other words we will need to scale the weights appropriately so that tasks that were never learned together (in the same training batch) can now appropriately compete when trained in isolation.

Finally, we use Wb and Wc to test our model in actual applications.
An improvement of CRW is CRW+ which removes the need to rescale the weight when copying from Wt to Wc. CRW+ instead subtracts the mean of the weights before copying them to Wc.
Architect and Regularize (AR1)
This method combines techniques of regularization such as CRW+ and architecture (Synaptic intelligence or SI). CRW+ alone had the requirement to freeze the Wb weights, which limits applicability and performance. In order to improve CRW+, the ability to change pre-trained weights was added using SI.
The effect of AR1 (CwR+Syn) is displayed in the figure below. This is on the CORe50 dataset. Other methods are also evaluated. Cumulative is the method where one creates a large dataset from all the dataset and trains from scratch.
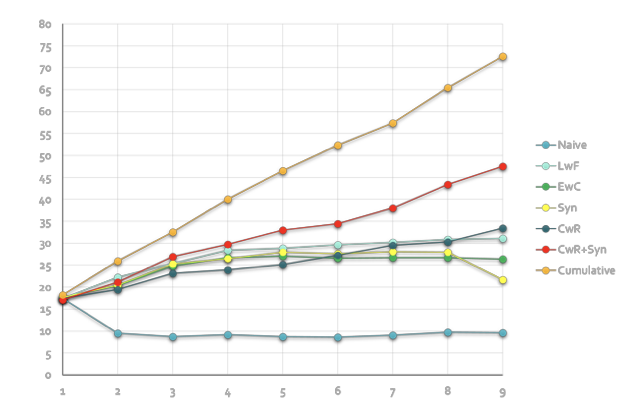
Training accuracy versus number of new tasks (classes) learned
Note: all this is material is from Vincenzo Lomonaco and his thesis work on continual and life-long learning (continualai)