Learning and performing in the real world — part 2
We have argued for the need to use predictive neural network to improve the learning abilities and speed of reinforcement learning algorithms — see part I.
We have introduced predictive neural network that can learn from video to predict next frames — see here. Initial results on reinforcement learning were encouraging.
The conundrum
But the big issue was always that predicting pixels in future frames is not really a good tasks that can help to learn about the environment beyond how things move in the image plane. Such network would just learn the basic of motion prediction used in MPEG! They would learn shallow neural network layers only, and fail to create meaningful representations of the input scene.
We immediately thought that a better way is to learn representations of the scene and predict such higher-level representations, not pixels! But the conundrum was always:
how can we train a network by optimizing prediction on its output if we need a networks int the first place to get such outputs!
A tale of two networks
There is a chicken-in-egg issue! This was solved by introducing another network and moving the problem to it! We can do this:
- use a network fi to encode inputs (frames, etc) x_t into embeddings fi(x_t)
- use a predictive network (PN) to predict future embeddings fi(x_t+1)
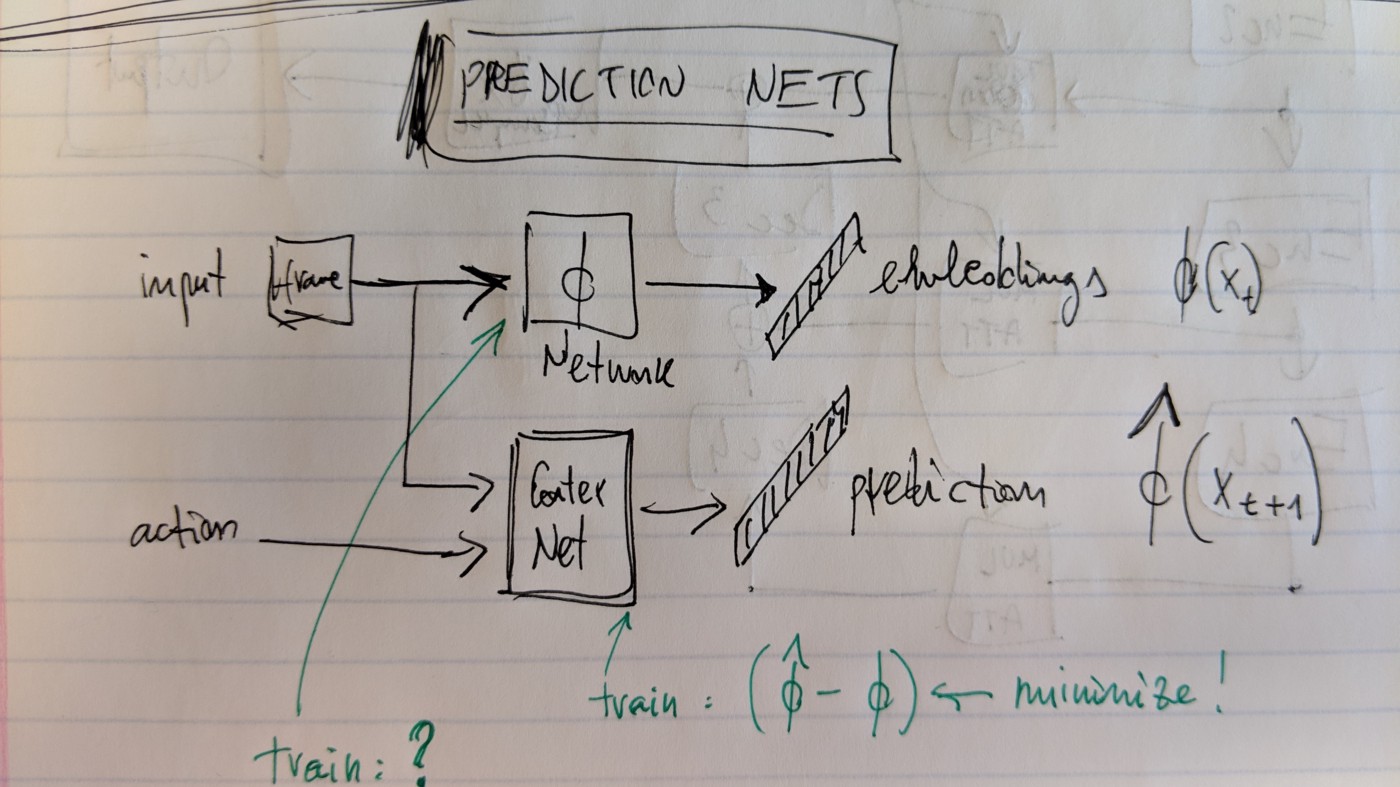
A predictive network for RL (reference)
See picture above, the conundrum still exists! We moved it to: how do we get the fi network?
What if we used a previous version of PN as fi? Meaning we could keep updating PN all the time, and periodically copy part of it as fi?