Biological and artificial intelligence
commentary on this blog post by Surya Ganguli

I wanted to provide some commentary on this blog post by Surya Ganguli, which appeared on December 5th 2018 (here: the “article”).
My background is neuromorphic microchip and system design as well as in deep-learning hardware and software for almost 20 years.
The post by Surya Ganguli is of great value and I recommend all interested in the topic to read it. I would like to provide some thoughts based on my experience and technology design path, so we can better prepare for a future where artificial intelligence will have learned all there is to learn from biological brains, and also be able to perform at or above biological intelligence levels.
Biologically plausible credit assignment
This section mentions the challenge of using more effective local learning rules. It says: “the brain solves it using a local learning rule”. Today, most deep learning models are trained with back-propagation that spans all layers in the networks. They can thus propagate effectively errors in the cost function to all the weights in the network in one single pass. In biological neural networks instead, from what is know to-date, learning occurs locally, confined between two layers and often between a small set of neurons and synapses.
Inventing and testing local learning techniques has been one of the algorithmic research work that we and many others are trying to tackle. Our group has worked on a techniques called Clustering Learning (see here and here) and culminated in Aysegul Dundar seminal work. These techniques all try to learn locally, on a layer by layer basis. There are many more, like auto-encoders, sparse-coding, belief networks, Boltzmann machines, and many more that paved the way.
Why are we mixing “unsupervised” and “local learning rules” here? Well because one way to train unsupervised is to reconstruct or work on layer-by-layer errors, and this is one form of unsupervised learning.
What did we learn by doing all this work and research? We learned that local learning function work well to pre-train neural network weights and that they can be very useful in cases where training data is scarce, and thus we need way to pre-train in an unsupervised manner. Hardly the case today, where deep learning dataset are large and many. Today we use these labeled dataset to train neural networks, and if you have a large dataset at your disposal back-propagation over many layers always beats any unsupervised and layer-by-layer learning techniques. And this is well known to all that work in deep learning today.
The question is: what do you do if you do not have such rich and large datasets? Well, then you have to use unsupervised learning techniques to bootstrap learning. We read, analyzed and reported on unsupervised learning techniques here. And we found something that may surprise many of you: the best unsupervised techniques still train networks end-to-end with back-propagation. Like the popular GAN these days. And this is interesting: back-propagating signals from many layers makes the signal more important that if you just used it in a single layer. That is because error signals can affect much more weights if back-propagated across many layers. Biology may or may not do this because of signal-to-noise issues, and nevertheless is restricted to using error signal only locally. In digital circuits we can do a bit better today because we can afford larger number of bits and higher noise thresholds. We will come back to this later in section “biology vs silicon hardware” to reflect on power efficiency and difference in materials also.
Where does this leave us with unsupervised techniques? These are still one only option if our dataset is tiny, and we have no way to use transfer-learning (learning in another large dataset that is close to our target dataset, and then transfer trained weights).
One final thought is that one can also trade off performance of unsupervised learning system for size, in some cases. This means that if you can afford making your unsupervised network much larger, you will surely come closer to its performance in a supervised setting with back-prop. You will still miss multi-layer adaptation (network weights optimization) that comes from propagating over multiple layers. But this means having more neurons and thus using more power.
And local-learning is also very inefficient for a more dramatic reason: it forgets that it learned some solutions in another areas of the brain and then has to learn it again in many localized area. Remember for example in the visual cortex orientation filters are learned over and over again in all of the spatial retinal maps like in V1 and probably beyond. This is largely inefficient.
The question is: would you rather have a small number of efficient neurons of many that are not? The brain evolved to the latter. I know, I know: you are thinking why is that the brain uses few watts of power and computers / AI chips take a power grid down? Ok, we will talk more about this later here.
Bottom line:
if you can back-propagate on many layers, do so!
Synaptic complexity
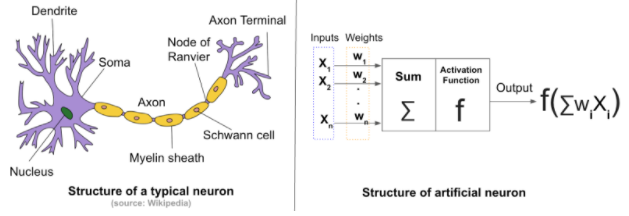
The article mentions that “ current AI systems are leaving major performance gains on the table by ignoring the dynamical complexity of biological synapses”. Biology uses synapses to communicate electrical pulses or spikes from one cell to the next. It does so by a complex chemical machine that releases neurotransmitters that in turn open or close pathways of ions into cells. In artificial neural networks, instead, we use wires.
My response is that of course deep learning uses complex synapses! The most basic form of synapse is a non-linear function that sits at the output of neurons. This function can model both the neuron non-linear threshold and also the synapse dynamics. If a separate synapse model is desired, a simple matrix can model it (or a 1x1 convolution).
There are also many different ways in which we take into account the effect of a synaptic model, both in inference and also in training. I will list here only a few:
- layer architecture
- different non-linearities
- different bit-width
- scaling and normalization
- drop-out and other regularization techniques
You may ask yourself: why did biology use complex transfer function in each synapse? Because it has to use different kind of cells and ions and materials depending on the are of the brain. Because it evolved over millions of years without a common blue-print. Because it had to re-invent the wheel every so few million years. Because one ion dynamics are different from another ion. Because … the list goes on.
But the main major point here is that synapses also can help a neuron transfer function by adding variability and introducing more dynamics. As such you see we agree with the author. Only you can thus create a neuron that uses learnable dynamics based on data, and thus combine the transfer function of neuron and synapse into one. And we have the current artificial neuron!
Deep learning aficionados will say that artificial synapses may be better than the fixed transfer function primitives of biological synapses, because the former are trained on data to provide the best function approximation.
Bottom line:
we do use synapse dynamics in artificial neural networks

Taking cues from systems-level modular brain architecture
The article mentions: “the remarkable modularity of the modern mammalian brain, conserved across species separated by 100 million years of independent evolution, suggests that this systems-level modularity might be beneficial to implement in AI systems”.
There is a large variety of neural architectural design that occurs every single days in the field of artificial neural networks, deep leaning. These are:
The advantage of artificial system is that we can experiment very rapidly today on many neural network architectures, to the point that we can even now search entire families of architectures automatically, with global optimization, and be able to create new and diverse sets of artificial primitives:
Again I also want to point out that biological brains do so at a very slow time scale of millions of years, without a plan, without a global controller other than daily rewards and survival, by using random searches that is horridly inefficient.
Bottom line:
artificial neural networks have a immensely large collection of primitives, modules, architectures that exceeds biology by far, if not today, in just a few more years
Biological and artificial hardware
Most of us forget that the human brain and artificial neural networks today are based on completely different sets of materials and chemical elements.
Brains are made of cells, and microchips are made in silicon and metal
If you only have cells immersed in a conductive ionic medium, transmitting electrical signal is hard for sure! Yet biological brains evolved to do just that. The had no other way to send signals across long distance but to do so with pulses. We talked about this a lot here and here. So that is really why biology uses spiking neural networks (1-bit signals, if you will). If it could signal with continuous levels without being swamped by noise, it would have! Because it would save a lot of energy.
In one sentence: biology has leaky squishy fluidy tubes used as wires, while silicon has metal wires with nice insulation. And this is the crux of the problem and the main difference of why one system has evolved in this way.
On the other hand electrical circuits used in todays computers are all digital and multi-bits. We started with analog signals too, just the old biological brains (and our eyes), because an analog signal has in theory infinite number of values (symbols) it can transmit. But then all infinite possibilities are narrowed to a few because of electronic fundamental noise, in the same way that electrical noise in biological medium forced it to become 1-bit pulses.
If you have 1-bit, how can you use it to represent many values? Time between pulses on one neuron or a group of many neurons of 1-bit can represent larger ensembles like in digital circuits.
You see: when you have neurons their output can have any number of bits you can afford in your system: 1-bit if you have to, or 4 or 8 or 16-bits if you can. And since many 1-bit neurons can represent larger bit numbers, then effectively you can decide:
do you want more 1-bit neurons or less multi-bit neurons?
The balance depends on which technological medium you use and all its parameters.
Remember back-propagation works better with many bits, as its neurons needs to store smaller and smaller numbers while back-propagating over many layers. Today, we can back-propagate with just 8–9 bits per neuron (and another 8 in common across a group of neurons).
Learning is of course also vastly affected by the medium at your disposal. In artificial neural networks signal can travel further and with more noise immunity, so multi-bits and less neurons are the way to go. Learning also can use these properties to afford algorithms such as back-propagation and more global optimization as opposed to local rules dominated by short-range signals in a leaky medium.
An biological brain evolved over millions of years by making the same mistakes many times and replicating solutions in many places with many differences that are more the product of random search than intelligent design (with this I mean a global system design that predated the actual realization). lol.
Do we have the best digital circuit we can have? It can always get smaller. One day transistors may be just a few atoms, if we find ways to combat thermal noise and scaling. And there are new materials and new silicon devices coming up. One thing is sure: it will be hard to swerve away from silicon-based technology given our investment over the last 60 years. I have no crystal sphere here, so time will tell.
Often we heard that comparison about bird wings: how in biology we have flapping wings and in airplanes we do not. Most here forget to take into account the differences in size and also in materials used in both system. Small wings made of feathers are light and easy to activate by muscles, but large metal wings are not easy to move and the material may not be able to withstand the large forces of motion because of material properties. These two are in fact so different that it almost makes no sense to compare them! This is really the same in case of neuron and synapses: their structure and operation make sense in one domain, but not necessarily in others.
Bottom line:
cells and silicon each have paths of their own

Learning speed
The article mentions “It is clear in all three cases that humans receive vastly smaller amounts of labelled training data” forgets the fact that these networks are relatively small compared to biological ones and that biology evolved over millions of years, so effectively the species had 1,000x or millions of time more time and samples to learn from!
I think the article makes a point that once you have trained architecture biological ones learn with much less data and time. This is trues if you do not consider all the time biological network took to evolve and all the myriad of experiences that evolution integrated in the DNA of creatures.
We ought to remember that a lot of artificial neural network training is done from scratch, from tabula rasa. But once you have trained an artificial neural network you can transfer its weight to a new but similar domain or application without having to train again from zero and thus needing much less samples and time.
Bottom line:
biology learns a lot slower and much more inefficiently than artificial ones trained end-to-end
Learning to operate in the real world
The article makes good points that we need new neural architectures and learning techniques that can learn to provide complex functionality in the real world with limited training samples, and while performing continual learning.
Predictive neural networks are already making ways into learning unsupervised complex environments while avoiding to have to train the bulk of parameters on very sparse rewards.
We talked about ways to learn and operate in the real world here and here and here. To summarize, we are still a long way from having robots explore large areas to find a target, or learn to do tasks like clean up a room or cook a meal.
The main missing ingredients on which the entire community is hard at work are:
- imitation learning from videos
- predictive networks to predict how environment and actor will change once an action is performed
- mental simulations: predictions of sequences, revisiting what learned in imitation
- self-learning experimenting with mental sims and real tests, the reward is both getting to a goal and also making the rights steps towards it
Q-learning, policy gradients, actor-critic etc algorithms were a good starting point, but do not possess the quality to scale to complex tasks.
It would be really great if we could learn from how the human brain learned to do these things, and how different parts of the brain cooperate to solve complex tasks. But we do not have the scientific tools to study learning on billions of neurons, nor the ability record from large neural populations (10,000 or more). Also, having worked in this area for quite some time in the past, I am unsure we even have a path to obtaining these tools in the next decades.

Energy efficiency
The article mentions “The human brain spends only 20 watts of power, while supercomputers operate in the megawatt range”. We have deep learning accelerator microchips that can perform trillions of operations per seconds, at the level of super-computers that operate in the same ball-park of the human brains. We may not have these devices today, but the ones, like myself, that are working on it have a path in current silicon technologies to provide complex capabilities, the most advanced ones that deep learning and AI currently provides, in a 10 watts envelope or below. Our company FWDXNTworks on such advanced systems, as well as many other companies such as Intel, NVIDIA, AMD, ARM, to name a few.
Bottom line:
the power efficiency gap between the human brain and what is possible in artificial neural networks is narrowing, and will soon converge to the limits of what physics allow

Conclusion
A comparison between artificial and biological neural networks is something we are drawn to often, and it makes some sense in some ways, for example when we have to take rough inspiration or when we want to compare to abilities in one or another species. In general, though, the two are diverging at a fast speed, due to the fact that we do not have good tools to study biological brains at scale, while we have very fast artificial tools we can experiment and create with quickly.
Final bottom line:
biological and artificial neural networks are made of very different material with very different properties and it only makes partial sense to compare their inner workings
Notes
PS 1: an older version of some of these discussions are here and here.
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…