Neural Networks Building Blocks
Neural networks are made of smaller modules or building blocks, similarly to atoms in matter and logic gates in digital circuits.
Once you know what the blocks are, you can combine them to solve a variety of problems. Many new building blocks are added constantly, as smart minds discover them
What are these blocks? How can we use them? Follow me…
Weights
Weights implement the product of an input i with a weight value w, to produce an output o. Seems easy, but addition and multiplications are at the hearth of neural networks.
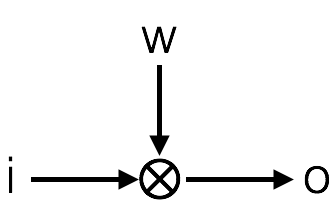
weights implement the product of an input i with a weight value w to give an output o
Neurons
Artificial neurons are one basic building block.

neuron, inputs i, output o, weight w
They sum up some inputs i and use a non-linearity (added as separate block) to output (o) a non-liner version of the sum.
Neurons use weights w to take inputs and scale them, before summing the values.
Identity layers
Identity layers just pass the input to the output. Seem pretty bare, but they are an essential block of neural networks.
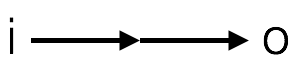
identity: i=o
See below why. You will not be disappointed!
Non-linearities
http://pytorch.org/docs/master/nn.html#non-linear-activations
They take the inner value of a neuron and transform it with a non-linerfunction to produce a neuron output.

non-linear module
The most popular are: ReLU, tang, sigmoid.
Linear layers
http://pytorch.org/docs/master/nn.html#linear-layers
These layers are an array of neurons. Each take multiple inputs and produce multiple outputs.
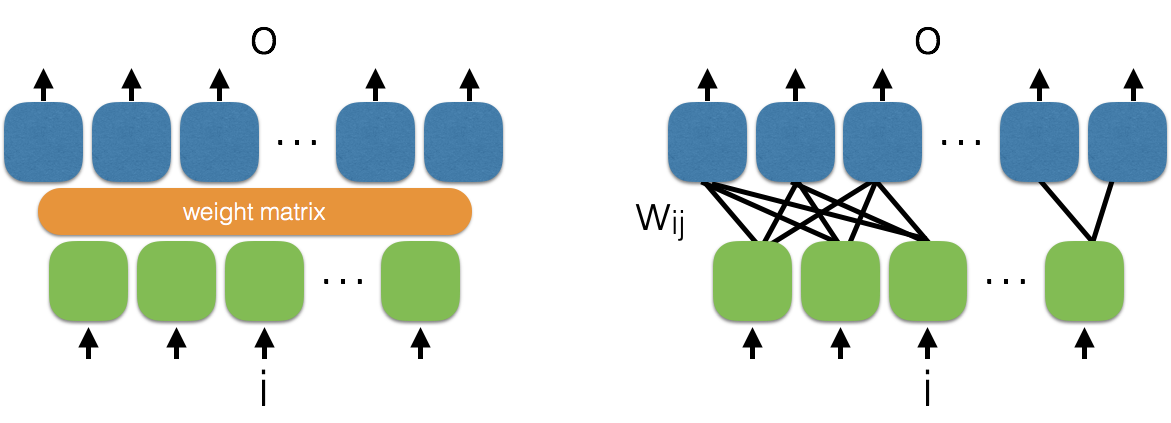
linear layer: input i and output o are vectors of any and different length. A weight matrix (left) and how it may be fully connected (right) show different version of the same linear layer.
The input and output number is arbitrary and of uncorrelated length.
These building blocks are basically an array of linear combinations of inputs scaled by weights. Weights multiply inputs with an array of weight values, and they are usually learned with a learning algorithm.
Linear layers do not come with non-linearities, you will have to add it after each layer. If you stack multiple layers, you will need a non-linearity between them, or they will all collapse to a single linear layer.
Convolutional layers
http://pytorch.org/docs/master/nn.html#convolution-layers
They are exactly like a linear layer, but each output neuron is connected to a locally constrained group of input neurons.
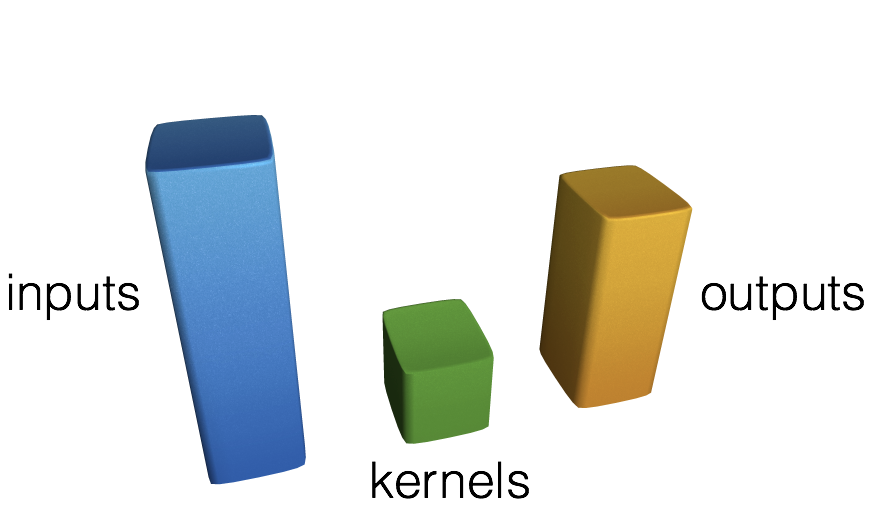
convolution is a 3d matrix operation: an inputs cuboid of data is multiplied by multiple kernels to produce an output cuboid of data. These are just a lot of multiplication and additions
This group is often called receptive-field, borrowing the name from neuroscience.
Convolutions can be performed in 1D, 2D, 3D… etc.
These basic block takes advantage of the local features of data, which are correlated in some kind of inputs. If the inputs are correlated, then it makes more sense to look at a group of inputs rather than a single value like in a linear layer. Linear layer can be thought of a convolutions with 1 value per filters.
Recurrent neural network
http://pytorch.org/docs/master/nn.html#rnn
Recurrent neural networks are a special kind of linear layer, where the output of each neuron is fed back ad additional input of the neuron, together with actual input.
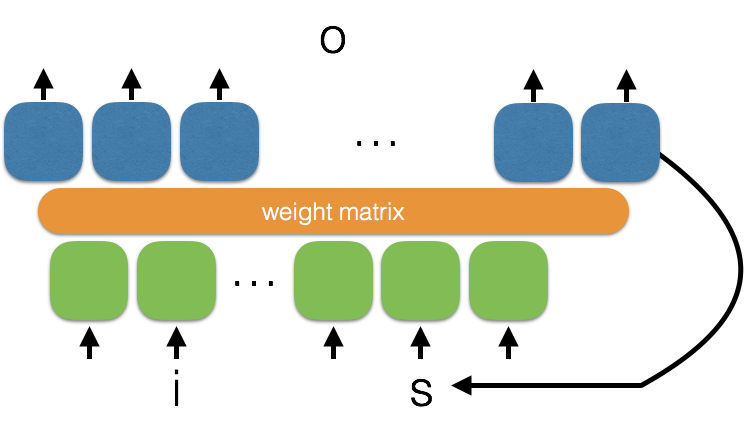
RNN: outputs or an additional state are fed back (values at time t-1) as an input together with input i (at time t)
You can think of RNN as a combination of the input at instant t and the state/output of the same neuron at time t-1.
RNN can remember sequences of values, since they can recall previous outputs, which again are linear combinations of their inputs.
Attention modules
Attention modules are simply a gating function for memories. If you want to specify which values in an array should be passed through attention, you use a linear layer to gate each input by some weighting function.
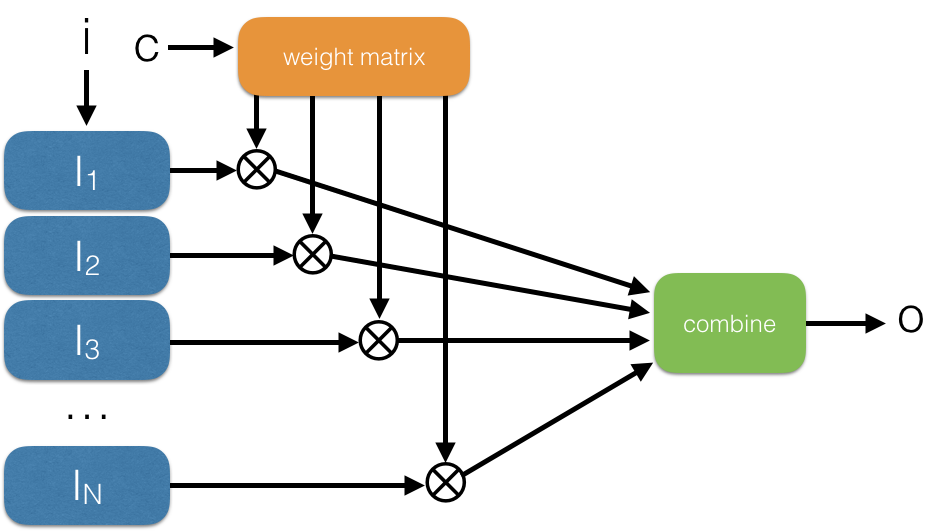
Attention module: an input i vector is linearly combined by multiplying each value by a weight matrix and producing one or multiple outputs
Attention modules can be soft when the weights are real-valued and the inputs are thus multiplied by values. Attention is hard when weight are binary, and inputs are either 0 or passing through. Outputs are also called attention head outputs. More info: nice blog post and another.
Memories
A basic building block that saves multiple values in a table.
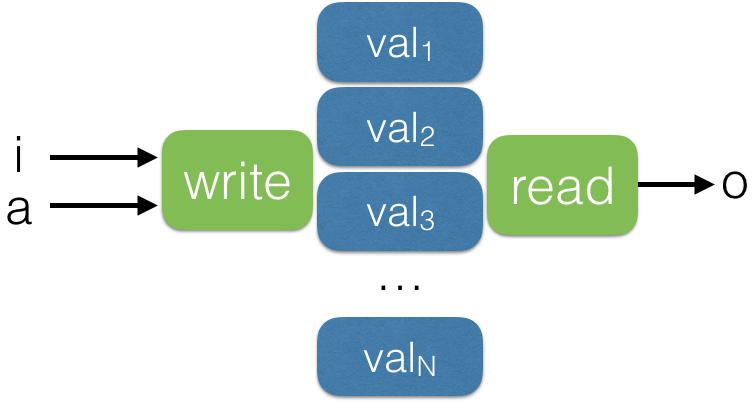
memory, input i, ouput o, optional addressing a
This is basically just a multi-dimensional array. The table can be of any size and any dimensions. It can also be composed of multiple banks or heads. Generally memory have a write function writes to all locations and reads from all location. An attention-like module can focus reading and writing to specific locations. See attention module below. More info: nice blog post.
Residual modules
Residual modules are a simple combination of layers and pass-through layers or Identity layers (ah-ah! told you they were important!).
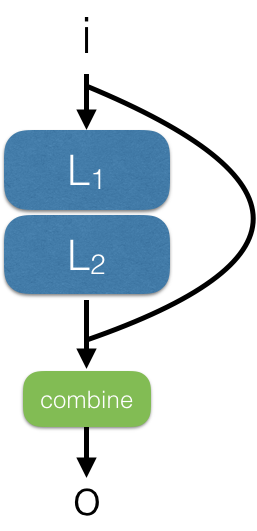
residual module can combine input with a cascade of other layers
They became famous in ResNet: https://arxiv.org/abs/1512.03385, and they have revolutionized neural networks since.
LSTM, GRU, etc.
http://pytorch.org/docs/master/nn.html#recurrent-layers
These units use an RNN, residual modules and multiple Attention modules to gate inputs, outputs and state values (and more) of an RNN, to produce augmented RNN that can remember longer sequence in the future. More info and figures: great post and nice blog post.
Neural networks
Now the hard part: how do you combine these modules to make neural networks that can actually solve interesting problems in the world?
So far it has been human smart minds that architected these neural networktopologies.
But why, did you not tell me that neural network were all about learning from data? And yet the most important things or all, the network architecture is still designed by hand? What?
This list will grow, stay tuned.
—
PS1: I do wish some smart minds can help me to find automatic ways to learn neural network architectures from data and the problem they need to solve.
If we can do this, we can also create machines that can build their own circuits topologies, and self-evolve. This would be a blast. And my work would be done. Ah, I can finally enjoy life!
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…