Analysis of deep neural networks for pixel processing — part One
By Dawood Sheik, Abhishek Chaurasia, Eugenio Culurciello
We measured the performance of the following bounding box detectors on MSCOCO 2017 validation set, number of parameters, number of FLOPS to achieve the published accuracy figures.
Bounding box architectures analyzed:
- SSD, YOLO: one stage encoder architectures which use classifier and regressor at the tail of the encoder to get the bounding box predictions. They both differ a little in their implementations and use different tricks to achieve their respective results. You can read more about them here: SSD, YOLOv2, YOLOv3
- RetinaNet: a one stage encoder-decoder architecture that uses bypass connections between the encoder and decoder to exploit the lower level features of the encoder. It uses a shared classifier and regressor at multiple decoder layers to get bounding box predictions. You can read more about RetinaNet here
- FasterRCNN, MaskRCNN: a two stage approach to object detection. It uses a region proposal network (RPN) to generate bounding box proposals. These proposals are sent through a classifier and a regressor in parallel to generate bounding box predictions. MaskRCNN extends FasterRCNN by predicting instance segmentation along with the classification and regression. You can read more about them here: FasterRCNN, MaskRCNN
Results:

mAP@0.5 per Million Parameters vs GOps, MParam
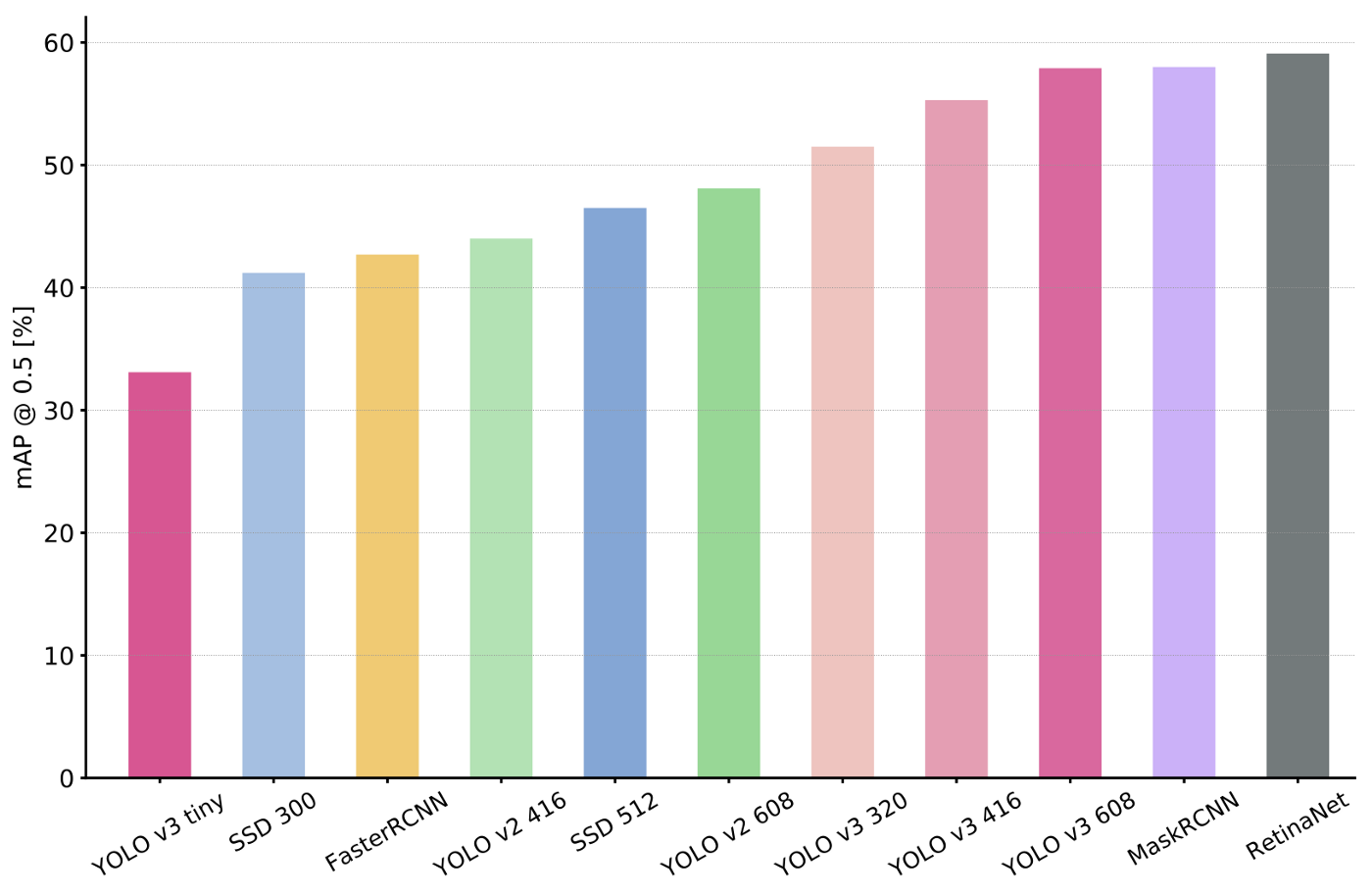
mAP@0.5 vs Network
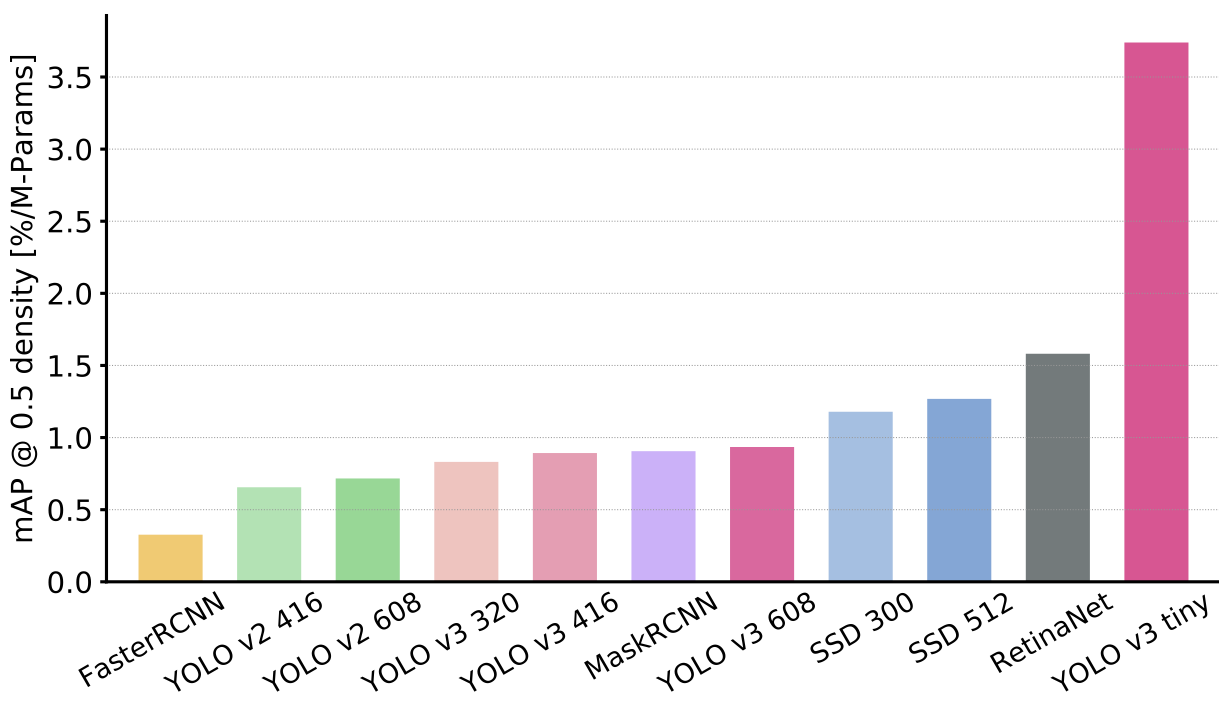
mAP@0.5 per Million Parameters vs Network
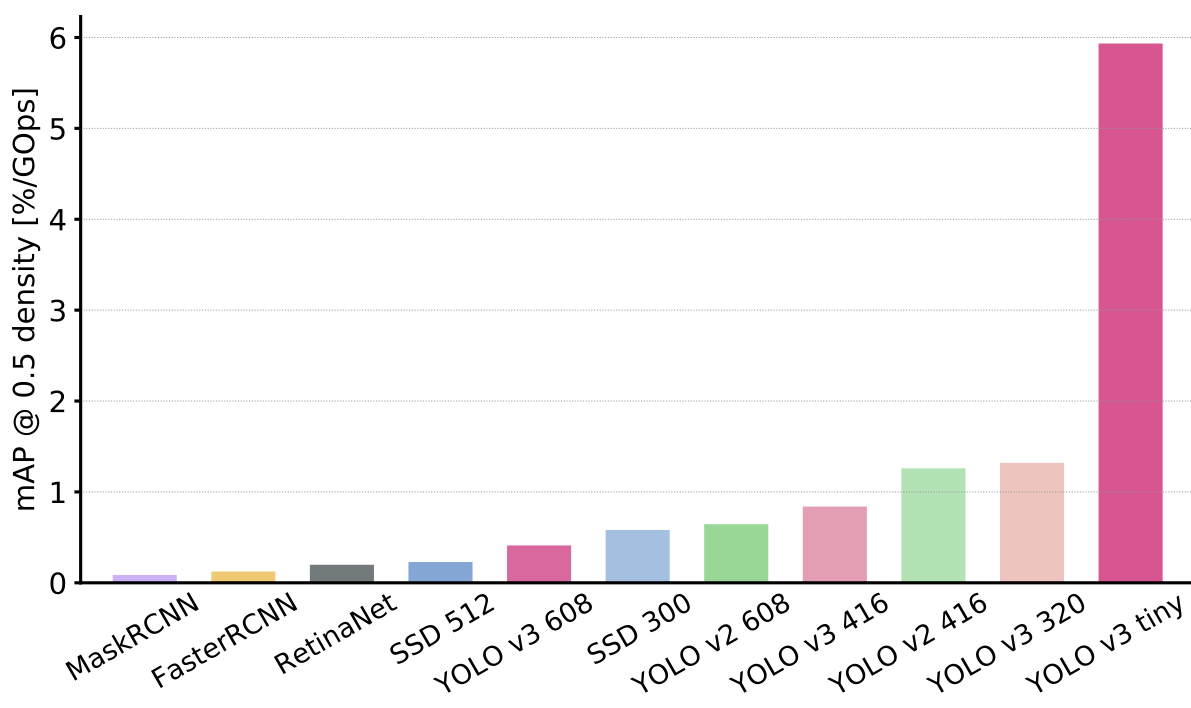
mAP@0.5 per GOps vs Network
Observations:
- Two stage approaches are bigger and take more operations to achieve similar accuracy as compared to one shot approaches. This is because two stage approaches have to run their classification and regression layers on all generated proposals, while the compute for one stage approaches remain constant regardless of the input image.
- Only diminishing returns in accuracy is achieved by increasing the number of operations on the same architecture (eg: Yolo v3 % increase in accuracy decreases with increase in ops)
Configuration tested:
Network, Image size, Comments
YOLO v2 416, 416 x 416,
YOLO v2 608, 608 x 608,
YOLO v3 tiny, 416 x 416,
YOLO v3 320, 320 x 320,
YOLO v3 416, 416 x 416,
YOLO v3 608, 608 x 608,
SSD 300, 300 x 300, VGG version
SSD 512, 512 x 512, VGG version
RetinaNet 800, 800 x 800, ResNet-101 FPN version
Faster RCNN, 600 x 850, VGG-16 version
Mask RCNN, 800 x 1024, ResNet-101 FPN version
For additional comparison between techniques, please see this article.
About the author
I have almost 20 years of experience in neural networks in both hardware and software (a rare combination). See about me here: Medium, webpage, Scholar, LinkedIn, and more…